


400 128 6709

行业新闻
 发布时间:2024-02-01
发布时间:2024-02-01 点击次数:
点击次数: TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者可以根据技术发展和需求差异,定制算子以满足特定需求,例如基于cutlass开发定制的GEMM。TensorRT-LLM是NVIDIA官方推理方案,致力于提供高性能并不断完善其实用性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

TensorRT-LLM在GitHub上开源,分为两个分支:Release branch和Dev branch。Release branch每月更新一次,而Dev branch会更频繁地更新来自官方或社区中的功能,方便开发者体验和评估最新功能。下图展示了TensorRT-LLM的框架结构,除了绿色TensorRT编译部分和涉及硬件信息的kernels外,其他部分都是开源的。

TensorRT-LLM 还提供了类似于 Pytorch 的 API 来降低开发者的学习成本,并提供了许多预定义好的模型供用户使用。
Pytorch 的 API 来降低开发者的学习成本,并提供了许多预定义好的模型供用户使用。

由于大语言模型的尺寸较大,可能无法在单张显卡上完成推理,因此TensorRT-LLM提供了两种并行机制:Tensor Parallelism和Pipeline Parallelism,以支持多卡或多机推理。这些机制允许将模型分割成多个部分,并将其分布在多个显卡或机器上进行并行计算,以提高推理性能。Tensor Parallelism通过将模型参数分布在不同设备上,并同时计算不同部分的输出来实现并行计算。而Pipeline Parallelism则将模型分割成多个阶段,每个阶段在不同设备上并行计算,将输出传递给下一个阶段,从而实现整体

TensorRT-LLM是一个强大的工具,具有丰富的模型支持和低精度推理功能。 首先,TensorRT-LLM支持主流的大语言模型,包括开发者完成的模型适配,比如Qwen(千问),并已纳入官方支持。这意味着用户可以轻松地基于这些预定义的模型进行扩展或定制,方便快捷地应用到自己的项目中。 其次,TensorRT-LLM默认采用FP16/BF16的精度推理方式。这种低精度推理不仅可以提高推理性能,还可以利用业界的量化方法进一步优化硬件吞吐。通过降低模型的精度,TensorRT-LLM可以在不牺牲太多准确性的前提下,大幅度提升推理的速度和效率。 综上所述,TensorRT-LLM的丰富模型支持和低精度推理功能使得它成为一个非常实用的工具。无论是对于开发者还是研究人员来说,TensorRT-LLM都能够提供高效的推理解决方案,帮助他们在深度学习应用中取得更好的性能表现。

另外一个特性就是 FMHA(fused multi-head attention) kernel 的实现。由于 Transformer 中最为耗时的部分是 self-attention 的计算,因此官方设计了 FMHA 来优化 self-attention 的计算,并提供了累加器分别为 fp16 和 fp32 不同的版本。另外,除了速度上的提升外,对内存的占用也大大降低。我们还提供了基于 flash attention 的实现,可以将 sequence-length 扩展到任意长度。

如下为 FMHA 的详细信息,其中 MQA 为 Multi Query Attention,GQA 为 Group Query Attention。
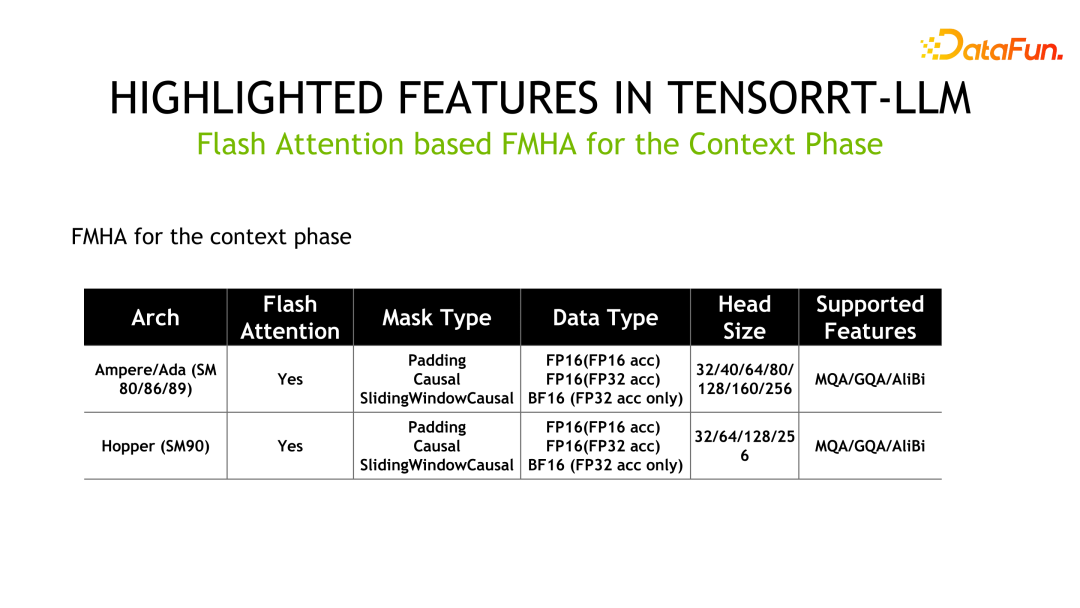
另外一个 Kernel 是 MMHA(Masked Multi-Head Attention)。FMHA 主要用在 context phase 阶段的计算,而 MMHA 主要提供 generation phase 阶段 attention 的加速,并提供了 Volta 和之后架构的支持。相比 FastTransformer 的实现,TensorRT-LLM 有进一步优化,性能提升高达 2x。

另外一个重要特性是量化技术,以更低精度的方式实现推理加速。常用量化方式主要分为 PTQ(Post Training Quantization)和 QAT(Quantization-aware Training),对于 TensorRT-LLM 而言,这两种量化方式的推理逻辑是相同的。对于 LLM 量化技术,一个重要的特点是算法设计和工程实现的 co-design,即对应量化方法设计之初,就要考虑硬件的特性。否则,有可能达不到预期的推理速度提升。

TensorRT 中 PTQ 量化步骤一般分为如下几步,首先对模型做量化,然后对权重和模型转化成 TensorRT-LLM 的表示。对于一些定制化的操作,还需要用户自己编写 kernels。常用的 PTQ 量化方法包括 INT8 weight-only、SmoothQuant、GPTQ 和 AWQ,这些方法都是典型的 co-design 的方法。

INT8 weight-only 直接把权重量化到 INT8,但是激活值还是保持为 FP16。该方法的好处就是模型存储2x减小,加载 weights 的存储带宽减半,达到了提升推理性能的目的。这种方式业界称作 W8A16,即权重为 INT8,激活值为 FP16/BF16——以 INT8 精度存储,以 FP16/BF16 格式计算。该方法直观,不改变 weights,容易实现,具有较好的泛化性能。

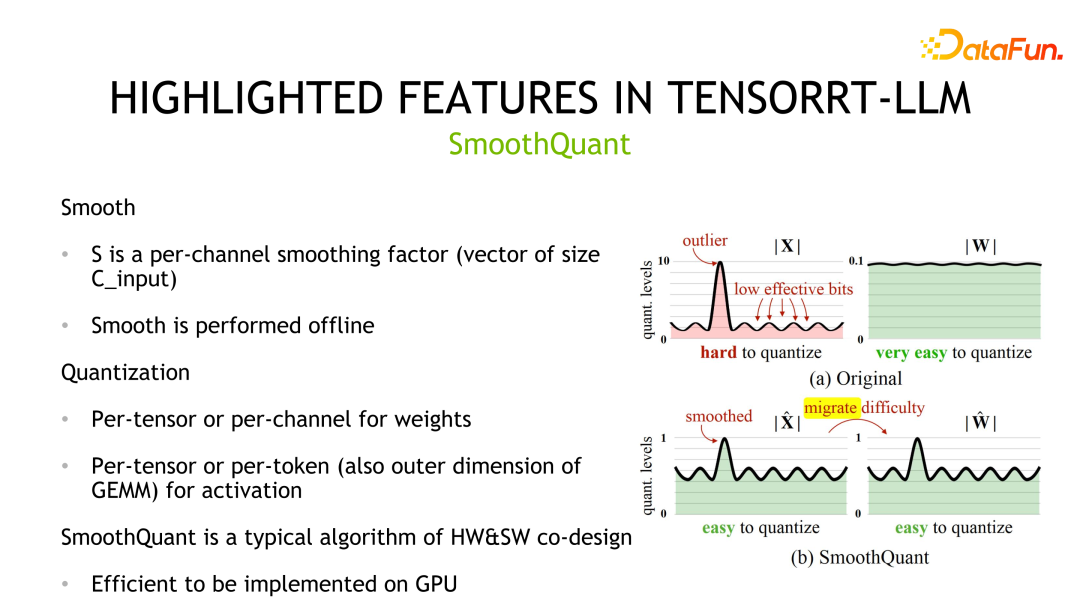
第二个量化方法是 SmoothQuant,该方法是 NVIDIA 和社区联合设计的。它观察到权重通常服从高斯分布,容易量化,但是激活值存在离群点,量化比特位利用不高。

SmoothQuant 通过先对激活值做平滑操作即除以一个scale将对应分布进行压缩,同时为了保证等价性,需要对权重乘以相同的 scale。之后,权重和激活都可以量化。对应的存储和计算精度都可以是 INT8 或者 FP8,可以利用 INT8 或者 FP8 的 TensorCore 进行计算。在实现细节上,权重支持 Per-tensor 和 Per-channel 的量化,激活值支持 Per-tensor 和 Per-token 的量化。
第三个量化方法是 GPTQ,一种逐层量化的方法,通过最小化重构损失来实现。GPTQ 属于 weight-only 的方式,计算采用 FP16 的数据格式。该方法用在量化大模型时,由于量化本身开销就比较大,所以作者设计了一些 trick 来降低量化本身的开销,比如 Lazy batch-updates 和以相同顺序量化所有行的权重。GPTQ 还可以与其他方法结合使用如 grouping 策略。并且,针对不同的情况,TensorRT-LLM 提供了不同的实现优化性能。具体地,对 batch size 较小的情况,用 cuda core 实现;相对地,batch size 较大时,采用 tensor core 实现。

第四种量化方式是 AWQ。该方法认为不是所有权重都是同等重要的,其中只有 0.1%-1% 的权重(salient weights)对模型精度贡献更大,并且这些权重取决于激活值分布而不是权重分布。该方法的量化过程类似于 SmoothQuant,差异主要在于 scale 是基于激活值分布计算得到的。


除了量化方式之外,TensorRT-LLM 另外一个提升性能的方式是利用多机多卡推理。在一些场景中,大模型过大无法放在单个 GPU 上推理,或者可以放下但是影响了计算效率,都需要多卡或者多机进行推理。

TensorRT-LLM 目前提供了两种并行策略,Tensor Parallelism 和 Pipeline Parallelism。TP 是垂直地分割模型然后将各个部分置于不同的设备上,这样会引入设备之间频繁的数据通讯,一般用于设备之间有高度互联的场景,如 NVLINK。另一种分割方式是横向切分,此时只有一个横前面,对应通信方式是点对点的通信,适合于设备通信带宽较弱的场景。

最后一个要强调的特性是 In-flight batching。Batching 是提高推理性能一个比较常用的做法,但在 LLM 推理场景中,一个 batch 中每个 sample/request 的输出长度是无法预测的。如果按照静态batching的方法,一个batch的时延取决于 sample/request 中输出最长的那个。因此,虽然输出较短的 sample/request 已经结束,但是并未释放计算资源,其时延与输出最长的那个 sample/request 时延相同。In-flight batching 的做法是在已经结束的 sample/request 处插入新的 sample/request。这样,不但减少了单个 sample/request 的延时,避免了资源浪费问题,同时也提升了整个系统的吞吐。

TensorRT-LLM 与 TensorRT的 使用方法类似,首先需要获得一个预训练好的模型,然后利用 TensorRT-LLM 提供的 API 对模型计算图进行改写和重建,接着用 TensorRT 进行编译优化,然后保存为序列化的 engine 进行推理部署。

以 Llama 为例,首先安装 TensorRT-LLM,然后下载预训练模型,接着利用 TensorRT-LLM 对模型进行编译,最后进行推理。

对于模型推理的调试,TensorRT-LLM 的调试方式与 TensorRT 一致。由于深度学习编译器,即 TensorRT,提供的优化之一是 layer 融合。因此,如果要输出某层的结果,就需要将对应层标记为输出层,以防止被编译器优化掉,然后与 baseline 进行对比分析。同时,每标记一个新的输出层,都要重新编译 TensorRT 的 engine。

对于自定义的层,TensorRT-LLM 提供了许多 Pytorch-like 算子帮助用户实现功能而不必自己编写 kernel。如样例所示,利用 TensorRT-LLM 提供的 API 实现了 rms norm 的逻辑,TensorRT 会自动生成 GPU 上对应的执行代码。

如果用户有更高的性能需求或者 TensorRT-LLM 并未提供实现相应功能的 building blocks,此时需要用户自定义 kernel,并封装为 plugin 供 TensorRT-LLM 使用。示例代码是将 SmoothQuant 定制 GEMM 实现并封装成 plugin 后,供 TensorRT-LLM 调用的示例代码。

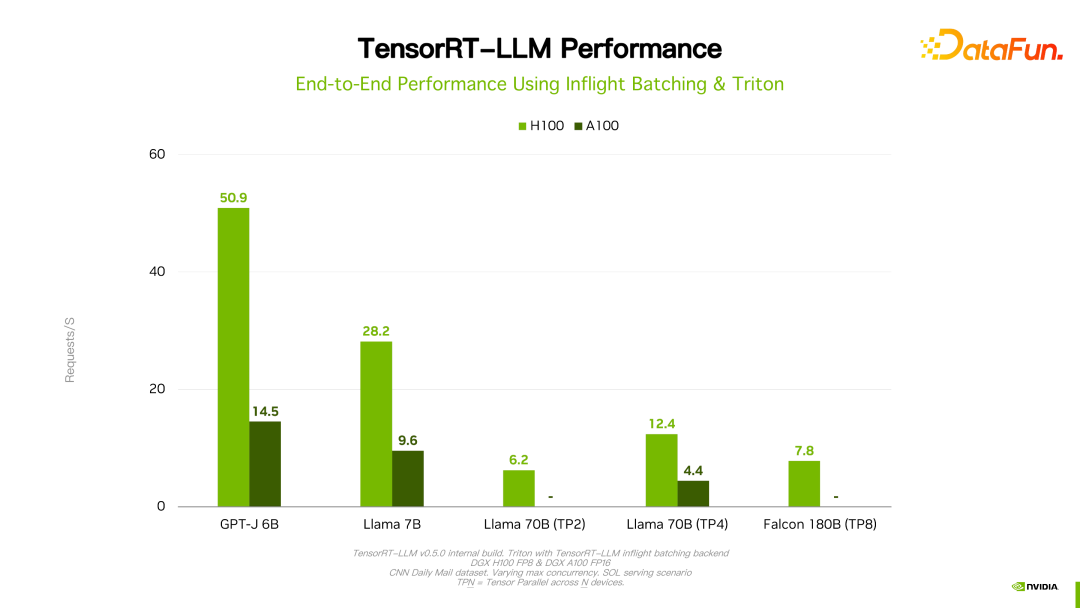
关于性能、配置等细节都可以在官网看到,在此不做详细介绍。该产品从立项开始一直与国内很多大厂都有合作。通过反馈,一般情况下,TensorRT-LLM 从性能角度来说是当前最好的方案。由于技术迭代、优化手段、系统优化等众多因素会影响性能,并且变化非常快,这里就不详细展开介绍 TensorRT-LLM 的性能数据。大家如果有兴趣,可以去官方了解细节,这些性能都是可复现的。
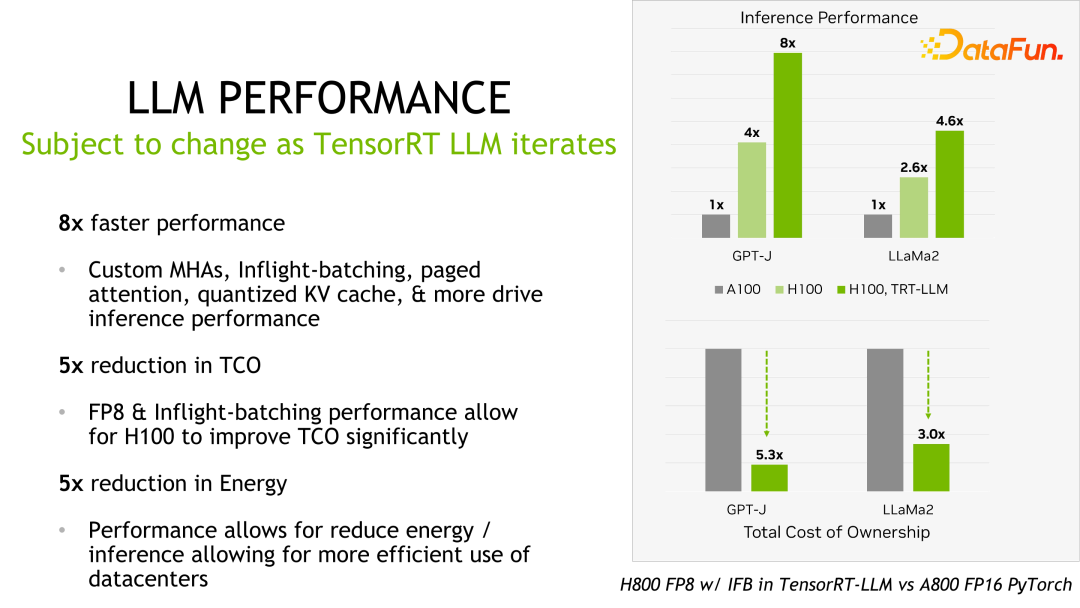
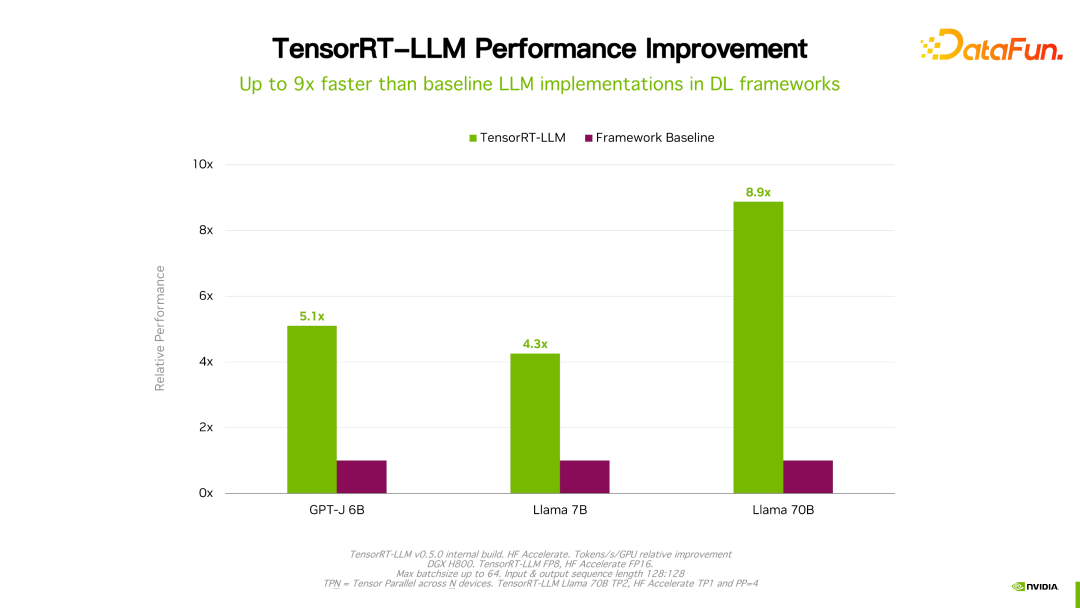
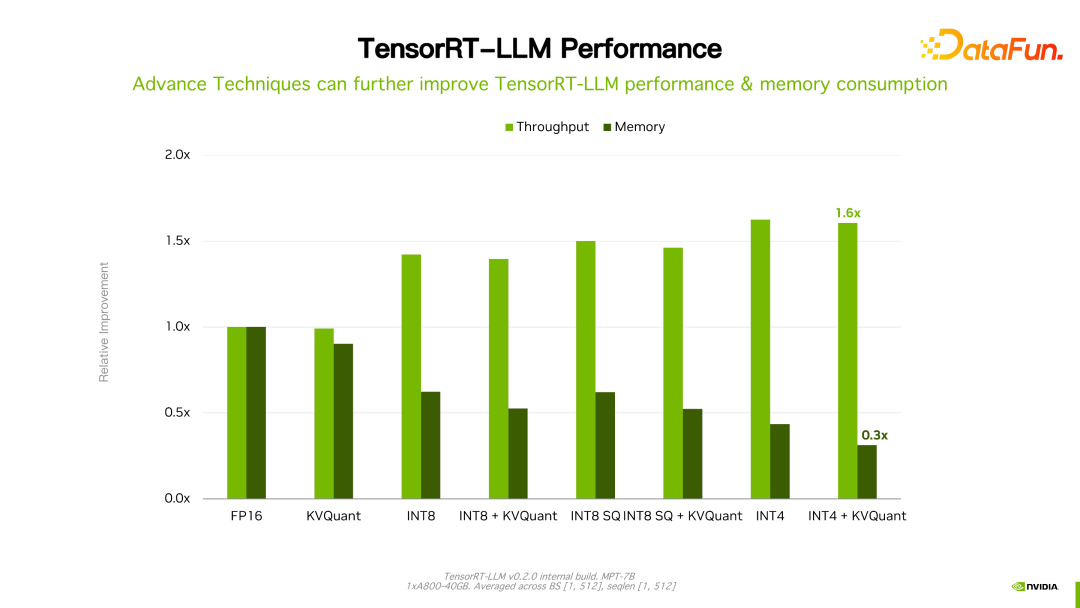
值得一提的是,TensorRT-LLM 跟自己之前的版本比,性能有持续地提升。如上图所示,在 FP16 基础上,采用了 KVQuant 后,速度一致的情况下降低了显存的使用量。使用 INT8,可以看到明显的吞吐的提升,同时显存用量进一步降低。可见,随着 TensorRT-LLM 优化技术的持续演进,性能会有持续地提升。这个趋势会持续保持。
LLM 是一个推理成本很高、成本敏感的场景。我们认为,为了实现下一个百倍的加速效果,需要算法和硬件的共同迭代,通过软硬件之间 co-design 来达到这个目标。硬件提供更低精度的量化,而软件角度则利用优化量化、网络剪枝等算法,来进一步提升性能。

TensorRT-LLM,将来 NVIDIA 会持续致力于提升 TensorRT-LLM 的性能。同时通过开源,收集反馈和意见,提高它的易用性。另外,围绕易用性,会开发、开源更多应用工具,如 Model zone 或者量化工具等,完善与主流框架的兼容性,提供从训练到推理和部署端到端的解决方案。

A1:目前 TensorRT-LLM 提供了两类方法,即 FP8 和刚才提到的 INT4/INT8 量化方法。低精度如果 INT8 做 GEMM 时,累加器会采用高精度数据类型,如 fp16,甚至 fp32 以防止 overflow。关于反量化,以 fp8 量化为例,TensorRT-LLM 优化计算图时,可能动自动移动反量化结点,合并到其它的操作中达到优化目的。但对于前面介绍的 GPTQ 和 QAT,目前是通过硬编码写在 kernel 中,没有统一量化或反量化节点的处理。
A2:目前的量化的确是这样,针对不同的模型做支持。我们有计划做一个更干净的api或者通过配置项的方式来统一支持模型的量化。
A3:因为一些功能未开源,如果是自己的 serving 需要做适配工作,如果是 triton 则是一套完整的方案。
A4:关于量化性能可以私下聊,关于效果,我们只做了基本的验证,确保实现的 kernel 没问题,并不能保证所有量化算法在实际业务中的结果,因为还有些无法控制的因素,比如量化用到的数据集及影响。关于 in-flight batching,是指在 runtime 的时候去检测、判断某个 sample/request 的输出是否结束。如果是,再将其它到达的 requests 插进来,TensorRT-LLM 不会也不能预告预测输出的长度。
A5:我们会尽量提供 c++ runtime 和 python runtime 一致的接口,已经在规划当中。之前团队的重点在提升性能、完善功能上,以后在易用性方面也会不断改善。这里不好直接跟 vllm 的比较,但是 NVIDIA 会持续加大在 TensorRT-LLM 开发、社区和客户支持的投入,为业界提供最好的 LLM 推理方案。
以上就是揭秘NVIDIA大模型推理框架:TensorRT-LLM的详细内容,更多请关注其它相关文章!
# 大模型
# 推理框架
# overflow
# qwen
# nvidia
# 奉贤seo优化有哪些
# 包头商城网站建设报价
# 英文网站建设报价多少
# 金州seo优化
# 网站推广平台大全
# 孟州优化网站建设
# 深圳抖音seo产品运营
# 十堰seo案例
# 隆化网站优化
# 谷歌的seo技术
# 还可以
# 会有
# 离线
# 是一个
# 另外一个
# 自己的
# 累加器
# 多个
# 开源
# 都是
# design
# llama
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
ChatGPT 可以设计机器人吗?
张勇对话多位诺奖得主 人工智能将无处不在
MiracleVision视觉大模型功能介绍
AI拉动PCB发展|行业发现
实践J*a开发,构建高性能的MongoDB数据迁移工具
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
奥比中光子公司和斯坦德机器人深度合作,共同推进新一代激光雷达的研发
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
阿里达摩院向公众免费开放100项AI专利许可
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
2025 WAIC|美团无人机发布第四代新机型
深度学习模型综述:用于3D MRI和CT扫描的应用
标贝科技亮相国际顶会ICASSP2025 加速布局海外AI数据市场
英伟达推出 L40S GPU,AI 推理性能超过 A100 约 1.2 倍
自研4D激光雷达L1 + GPT大语言模型 宇树Unitree Go2四足机器人有啥黑科技?
如布AI口袋学习机S12 将亮相综艺节目《好样的!国货》
苹果式 AI 哲学:不着一字,处处落子
MetaGPT开源框架爆红 GitHub,达到1.1万星,模拟软件开发流程
消息称字节机器人团队已有约50人,计划年底扩充到上百人
首届亚太网络法实务大会召开 九位大咖探讨元宇宙与人工智能发展
改变城市交通:智慧城市中的智能交通
华为发布大模型时代AI存储新品
创新全场景清洁方案!海尔商用机器人首发上市
腾讯机器狗进化:通过深度学习掌握自主决策能力
“苏南 vs 苏北” AI 分胜负,娱乐性比较工具 EitherChoice 上线
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会
标小智LOGO推出AI公司起名生成器“Name.GPT”
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
消息称 Meta Quest 将推 VR 游戏订阅:每月 7.99 美元,任选两款
AI在教育中的角色:AI如何改变我们的学习方式
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
13 个提高生产力的 AI 工具
RoboNeo操作教程
WHEE上线时间介绍
华为余承东表示:鸿蒙可能拥有强大的人工智能大模型能力
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
借助ChatGPT快速上手ElasticSearch dsl
城市在采用人工智能方面进展如何?
Win11 的画图应用将包含 Windows Copilot 的 AI 工具整合
码刻 | 48小时Hackathon,源码见证新生代AI创新的发生
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
映宇宙集团执行总编辑:元宇宙还是要以人为媒介
江永:精准施训提升通信无人机应急救援能力
昌吉市利用无人机实现全天候河道动态巡检
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
会模仿笔迹的AI,为你创造专属字体
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
Midjourney创始人:AI应该成为人类思想的延伸
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

