


400 128 6709

行业新闻
 发布时间:2023-08-14
发布时间:2023-08-14 点击次数:
点击次数: 近日,深度学习领域知名研究者、lightning ai 的首席人工智能教育者 sebastian raschka 在 cvpr 2025 上发表了主题演讲「scaling pytorch model training with minimal code changes」。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

为了能与更多人分享研究成果,Sebastian Raschka 将演讲整理成一篇文章。文章探讨了如何在最小代码更改的情况下扩展 PyTorch 模型训练,并表明重点是利用混合精度(mixed-precision)方法和多 GPU 训练模式,而不是低级机器优化。
文章使用视觉 Transformer(ViT)作为基础模型,ViT 模型在一个基本数据集上从头开始,经过约 60 分钟的训练,在测试集上取得了 62% 的准确率。
GitHub 地址:https://github.com/rasbt/cvpr2025
以下是文章原文:
在接下来的部分中,Sebastian 将探讨如何在不进行大量代码重构的情况下改善训练时间和准确率。
想要注意的是,模型和数据集的详细信息并不是这里的主要关注点(它们只是为了尽可能简单,以便读者可以在自己的机器上复现,而不需要下载和安装太多的依赖)。所有在这里分享的示例都可以在 GitHub 找到,读者可以探索和重用完整的代码。
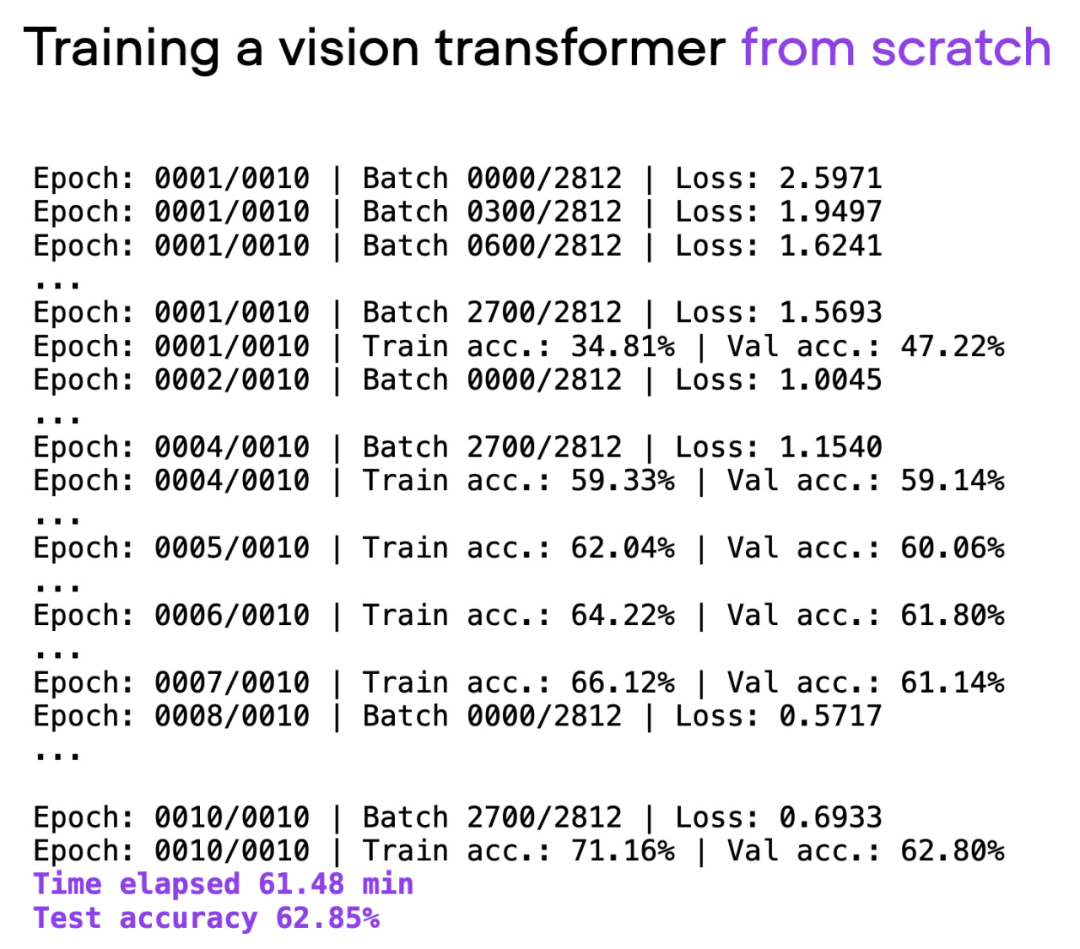
脚本 00_pytorch-vit-random-init.py 的输出。
现如今,从头开始训练文本或图像的深度学习模型通常是低效的。我们通常会利用预训练模型,并对模型进行微调,以节省时间和计算资源,同时获得更好的建模效果。
如果考虑上面使用的相同 ViT 架构,在另一个数据集(ImageNet)上进行预训练,并对其进行微调,就可以在更短的时间内实现更好的预测性能:20 分钟(3 个训练 epoch)内达到 95% 的测试准确率。
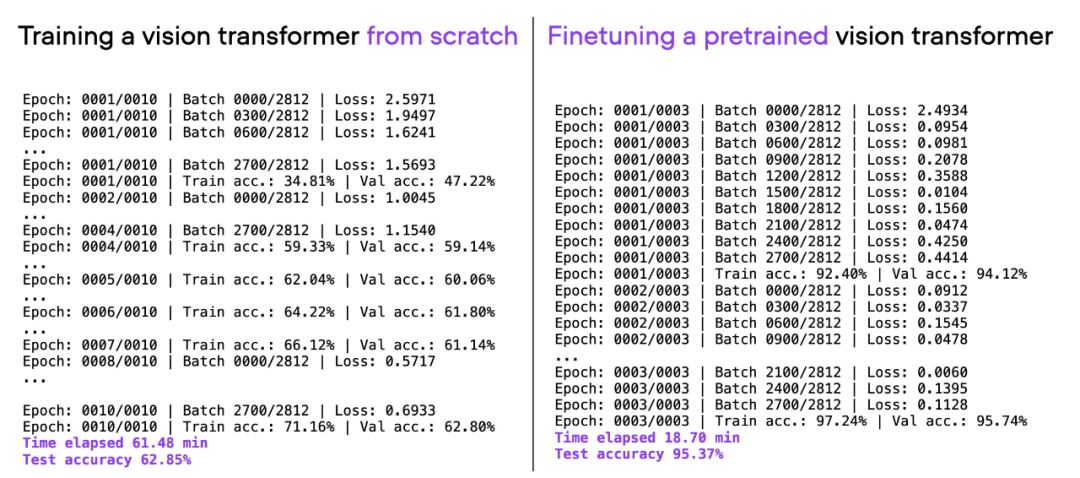
00_pytorch-vit-random-init.py 和 01_pytorch-vit.py 的对比。
我们可以看到,相对于从零开始训练,微调可以大大提升模型性能。下面的柱状图总结了这一点。
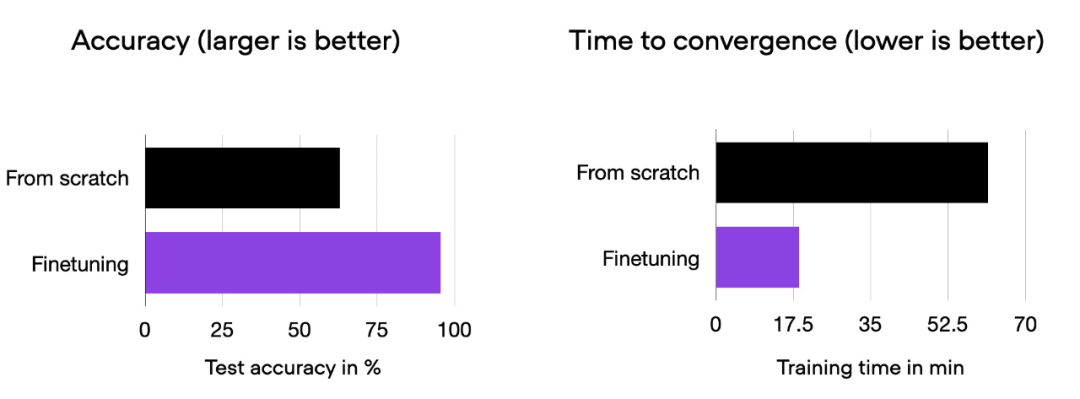
00_pytorch-vit-random-init.py 和 01_pytorch-vit.py 的对比柱状图。
当然,模型效果可能因数据集或任务的不同而有所差异。但对于许多文本和图像任务来说,从一个在通用公共数据集上预训练的模型开始是值得的。
接下来的部分将探索各种技巧,以加快训练时间,同时又不牺牲预测准确性。
在 PyTorch 中以最小代码更改来高效扩展训练的一种方法是使用开源 Fabric 库,它可以看作是 PyTorch 的一个轻量级包装库 / 接口。通过 pip 安装。
pip install lightning
下面探索的所有技术也可以在纯 PyTorch 中实现。Fabric 的目标是使这一过程更加便利。
在探索「加速代码的高级技术」之前,先介绍一下将 Fabric 集成到 PyTorch 代码中需要进行的小改动。一旦完成这些改动,只需要改变一行代码,就可以轻松地使用高级 PyTorch 功能。
PyTorch 代码和修改后使用 Fabric 的代码之间的区别是微小的,只涉及到一些细微的修改,如下面的代码所示:
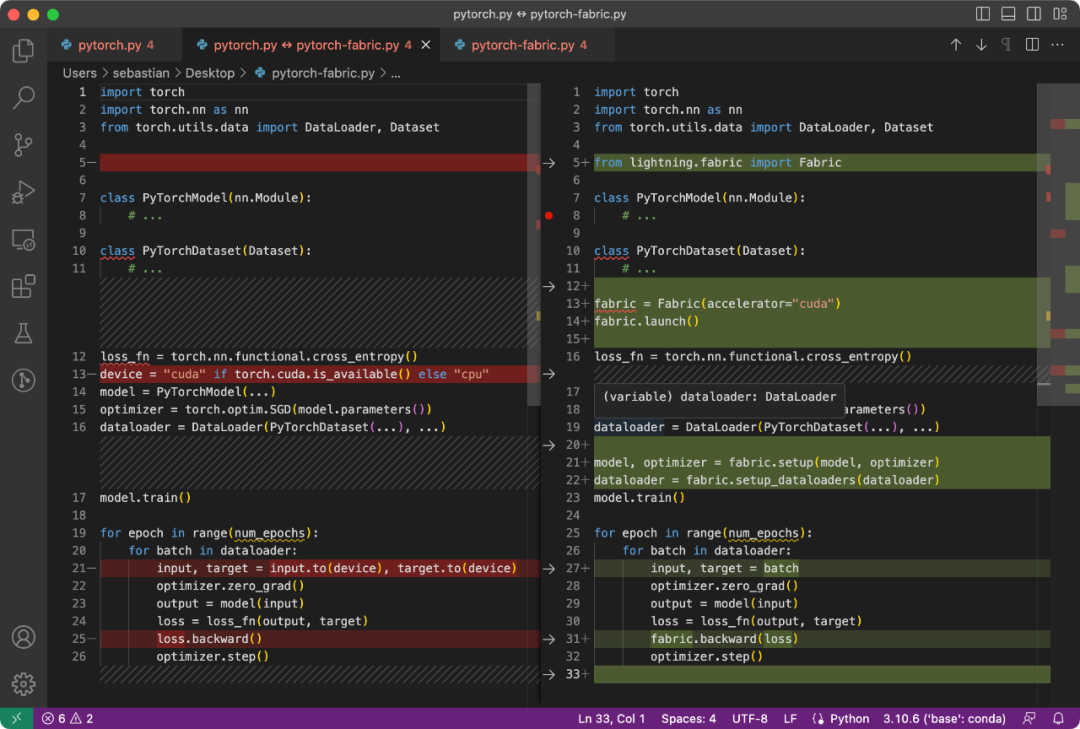
普通 PyTorch 代码(左)和使用 Fabric 的 PyTorch 代码
总结一下上图,就可以得到普通的 PyTorch 代码转换为 PyTorch+Fabric 的三个步骤:

这些微小的改动提供了一种利用 PyTorch 高级特性的途径,而无需对现有代码进行进一步重构。
深入探讨下面的「高级特性」之前,要确保模型的训练运行时间、预测性能与之前相同。
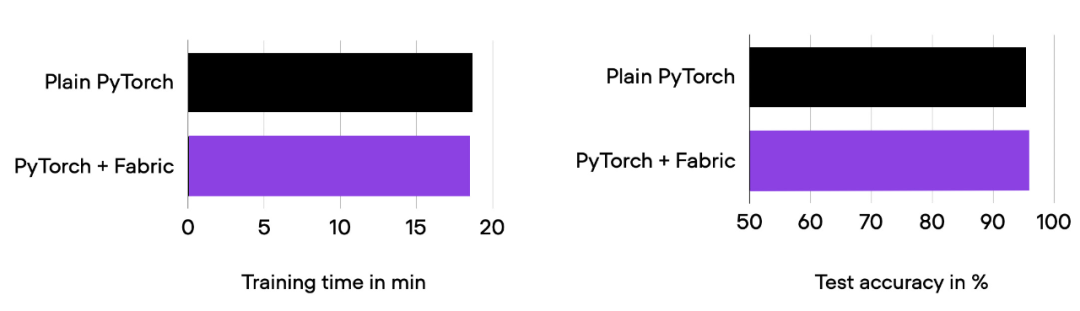
01_pytorch-vit.py 和 03_fabric-vit.py 的比较结果。
正如前面柱状图中所看到的,训练运行时间、准确率与之前完全相同,正如预期的那样。其中,任何波动都可以归因于随机性。
在前面的部分中,我们使用 Fabric 修改了 PyTorch 代码。为什么要费这么大的劲呢?接下来将尝试高级技术,比如混合精度和分布式训练,只需更改一行代码,把下面的代码
fabric = Fabric(accelerator="cuda")
改为
fabric = Fabric(accelerator="cuda", precisinotallow="bf16-mixed")
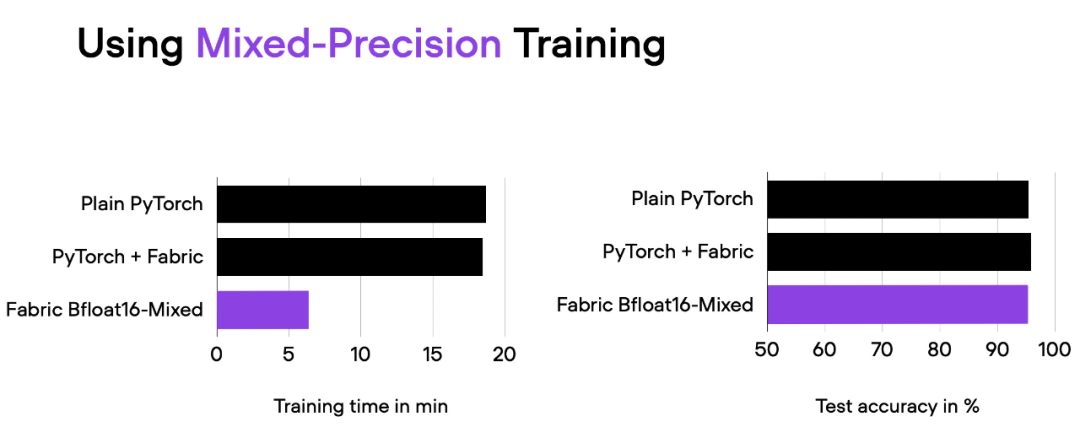
04_fabric-vit-mixed-precision.py 脚本的比较结果。脚本地址:https://github.com/rasbt/cvpr2025/blob/main/04_fabric-vit-mixed-precision.py
通过混合精度训练,我们将训练时间从 18 分钟左右缩短到 6 分钟,同时保持相同的预测性能。这种训练时间的缩短只需在实例化 Fabric 对象时添加参数「precisinotallow="bf16-mixed"」即可实现。
 网易人工智能
网易人工智能
网易数帆多媒体智能生产力平台
 233
查看详情
233
查看详情

混合精度训练实质上使用了 16 位和 32 位精度,以确保不会损失准确性。16 位表示中的计算梯度比 32 位格式快得多,并且还节省了大量内存。这种策略在内存或计算受限的情况下非常有益。
之所以称为「混合」而不是「低」精度训练,是因为不是将所有参数和操作转换为 16 位浮点数。相反,在训练过程中 32 位和 16 位操作之间切换,因此称为「混合」精度。
如下图所示,混合精度训练涉及步骤如下:
这种方法在保持神经网络准确性和稳定性的同时,实现了高效的训练。
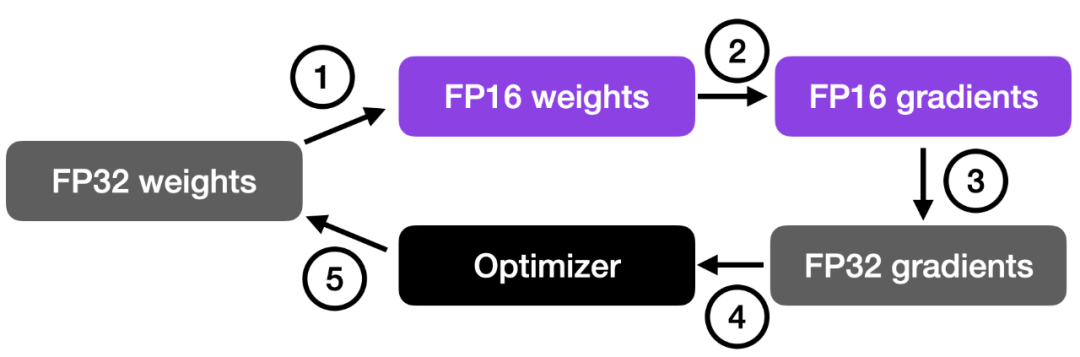
更详细的步骤如下:
步骤 4 中的乘积用于更新原始的 FP32 神经网络权重。学习率有助于控制优化过程的收敛性,对于实现良好的性能非常重要。
前面谈到了「float 16-bit」精度训练。需要注意的是,在之前的代码中,指定了 precisinotallow="bf16-mixed",而不是 precisinotallow="16-mixed"。这两个都是有效的选项。
在这里,"bf16-mixed" 中的「bf16」表示 Brain Floating Point(bfloat16)。谷歌开发了这种格式,用于机器学习和深度学习应用,尤其是在张量处理单元(TPU)中。Bfloat16 相比传统的 float16 格式扩展了动态范围,但牺牲了一定的精度。
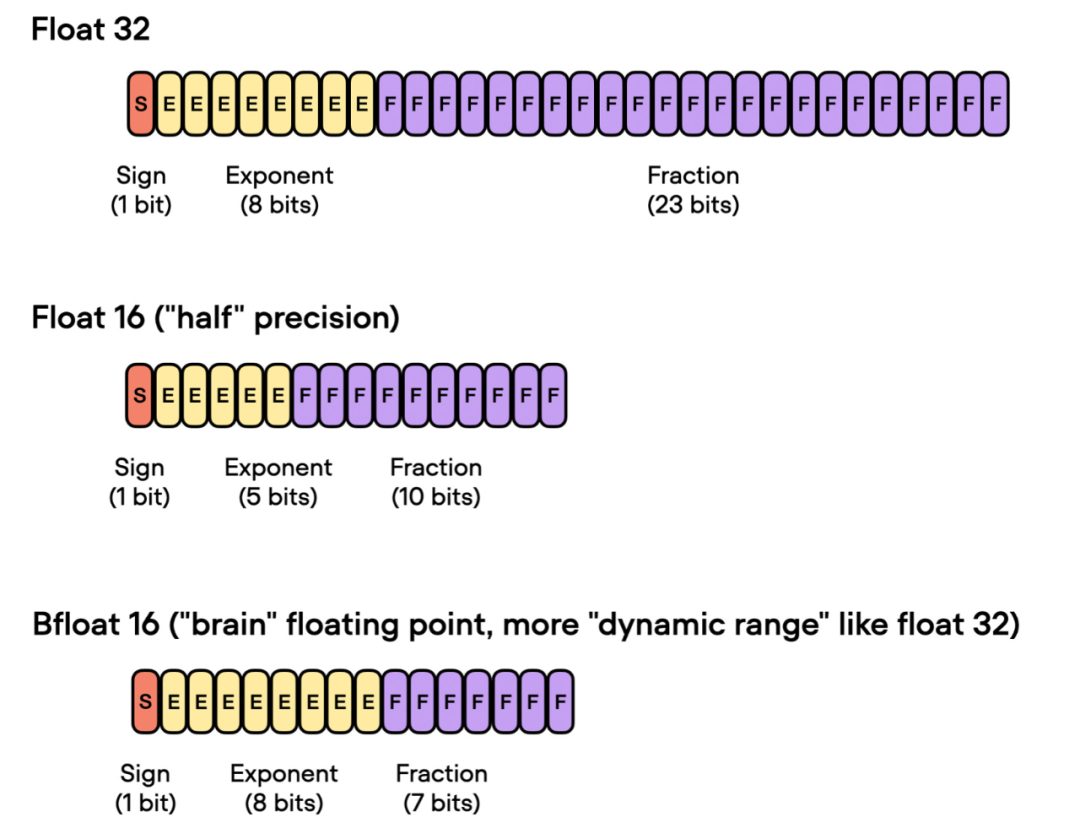
扩展的动态范围使得 bfloat16 能够表示非常大和非常小的数字,使其更适用于深度学习应用中可能遇到的数值范围。然而,较低的精度可能会影响某些计算的准确性,或在某些情况下导致舍入误差。但在大多数深度学习应用中,这种降低的精度对建模性能的影响很小。
虽然 bfloat16 最初是为 TPU 开发的,但从 NVIDIA Ampere 架构的 A100 Tensor Core GPU 开始,已经有几种 NVIDIA GPU 开始支持 bfloat16。
我们可以使用下面的代码检查 GPU 是否支持 bfloat16:
>>> torch.cuda.is_bf16_supported()True
如果你的 GPU 不支持 bfloat16,可以将 precisinotallow="bf16-mixed" 更改为 precisinotallow="16-mixed"。
接下来要尝试修改多 GPU 训练。如果我们有多个 GPU 可供使用,这会带来好处,因为它可以让我们的模型训练速度更快。
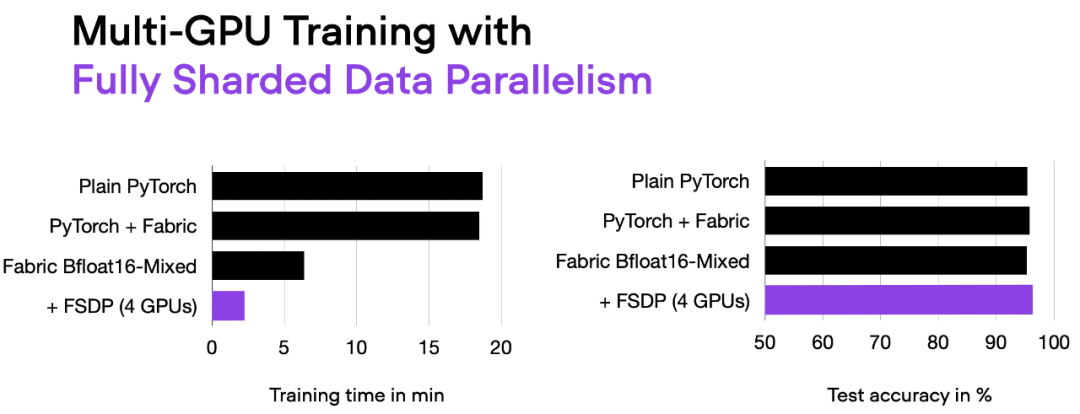
这里介绍一种更先进的技术 — 完全分片数据并行(Fully Sharded Data Parallelism (FSDP)),它同时利用了数据并行性和张量并行性。

在 Fabric 中,我们可以通过下面的方式利用 FSDP 添加设备数量和多 GPU 训练策略:
fabric = Fabric(accelerator="cuda", precisinotallow="bf16-mixed",devices=4, strategy="FSDP"# new!)
06_fabric-vit-mixed-fsdp.py 脚本的输出。
现在使用 4 个 GPU,我们的代码运行时间大约为 2 分钟,是之前仅使用混合精度训练时的近 3 倍。
在数据并行中,小批量数据被分割,并且每个 GPU 上都有模型的副本。这个过程通过多个 GPU 的并行工作来加速模型的训练速度。
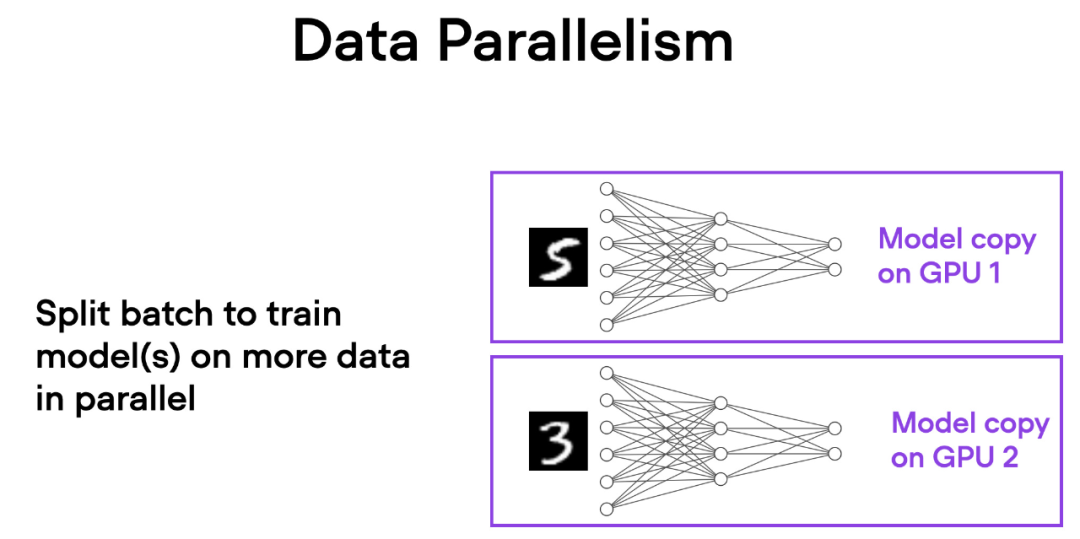
如下简要概述了数据并 行的工作原理:
行的工作原理:
每个 GPU 都在并行地处理不同的数据子集,通过梯度的平均化和参数的更新,整个模型的训练过程得以加速。
这种方法的主要优势是速度。由于每个 GPU 同时处理不同的小批量数据,模型可以在更短的时间内处理更多的数据。这可以显著减少训练模型所需的时间,特别是在处理大型数据集时。
然而,数据并行也有一些限制。最重要的是,每个 GPU 必须具有完整的模型和参数副本。这限制了可以训练的模型大小,因为模型必须适应单个 GPU 的内存。这对于现代的 ViTs 或 LLMs 来说这是不可行的。
与数据并行不同,张量并行将模型本身划分到多个 GPU 上。并且在数据并行中,每个 GPU 都需要适 应整个模型,这在训练较大的模型时可能成为一个限制。而张量并行允许训练那些对单个 GPU 而言可能过大的模型,通过将模型分解并分布到多个设备上进行训练。
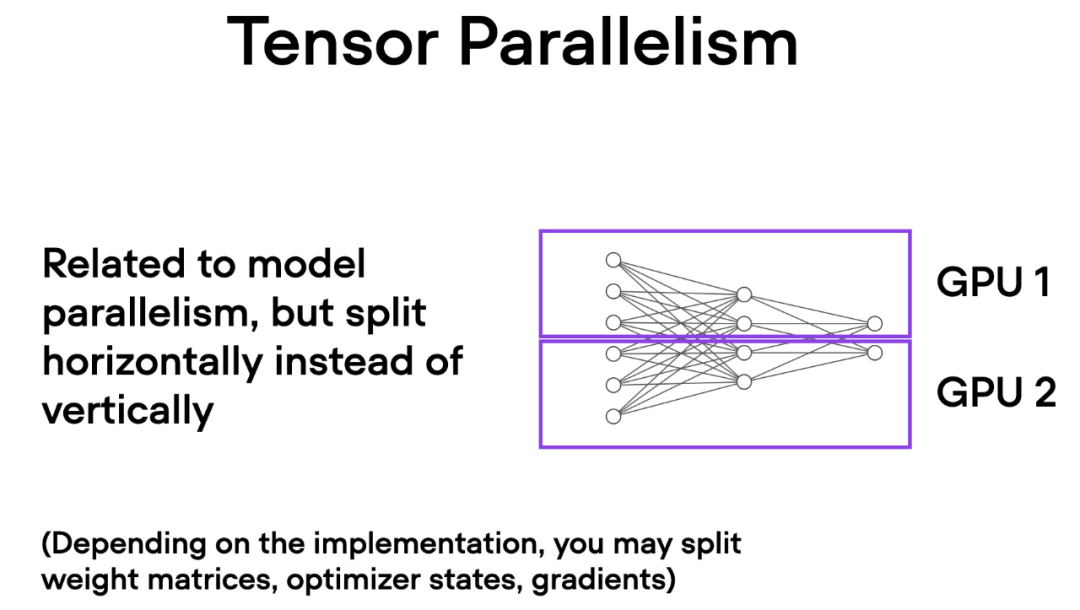
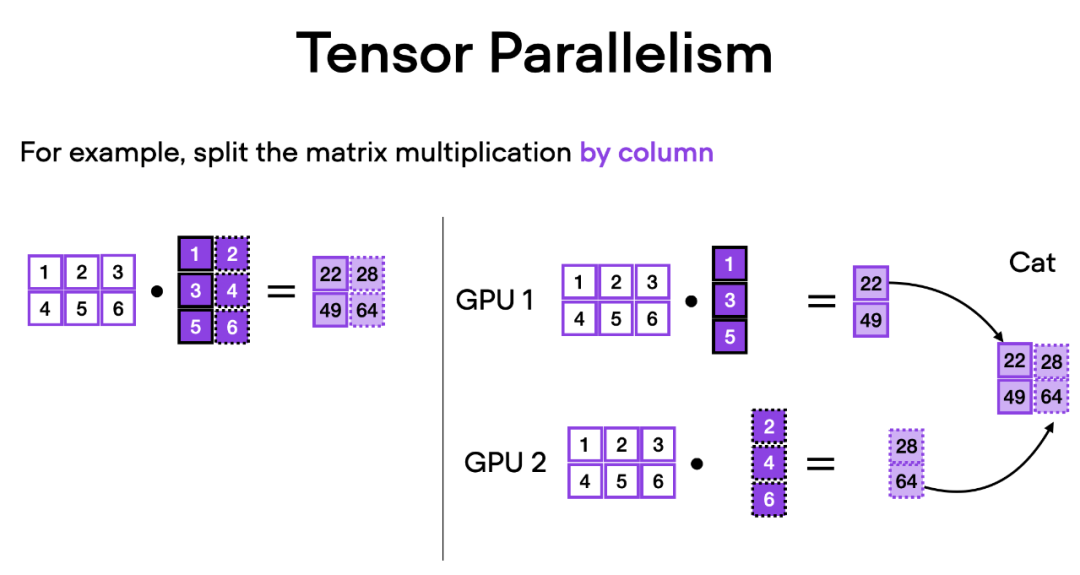
张量并行是如何工作的呢?想象一下矩阵乘法,有两种方式可以进行分布计算 —— 按行或按列。为了简单起见,考虑按列进行分布计算。例如,我们可以将一个大型矩阵乘法操作分解为多个独立的计算,每个计算可以在不同的 GPU 上进行,如下图所示。然后将结果连接起来以获取结果,这有效地分摊了计算负载。
以上就是改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键的详细内容,更多请关注其它相关文章!
# 所示
# 杭州seo网站推广找行者SEO
# 深圳哪些网站推广
# 威海营销推广策划价格
# 薯条营销推广版文案范文
# 德国家电网站知乎推广
# 泰安网站建设规划
# 商务网站建设报告范文
# seo网站优化外包费用
# 广州刷关键词排名
# 河北网站优化优势
# 模型
# 中国科学院
# 而不是
# 的是
# 重构
# 开源
# 转换为
# 较低
# 网易
# 多个
# 训练
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
讯飞星火大模型实现升级 助力通用人工智能人才培养
《流浪地球2》里机器人公司的创始人:未来10年,机器人的崛起!
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
大厂出品!这个AI网站太顶了,所有功能免费用
科学家称,面对人工智能,人类未来或只有灭亡与虚拟永生两个选择
严打“黑飞”,无人机检测反制设备护航大运会净空安全
国家发改委组织工业机器人产业高质量发展现场会
Valve 将拒绝采用 AI 生成未知版权内容的游戏上架 Steam
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
V社谈AI制作游戏被ban:为确保开发者有素材所有权
“上海市民营企业人工智能赋能创新中心”揭牌成立
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
Nature封面:量子计算机离实际应用还有两年
华为联合合作伙伴 共同发布昇腾AI大模型训推一体化解决方案
沐曦首款AI推理GPU亮相:INT8算力达160TOPS!
Bing 聊天机器人现支持在桌面端用语音提问
轻量级的深度学习框架Tinygrad
英伟达首席执行官黄仁勋:生成式 AI 时代「人类」会是新的编程语言
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
AI技术加速迭代:周鸿祎视角下的大模型战略
机构:边缘AI或是当前预期差最大的AI方向
日媒关注中国推进鸟类识别 AI 普及,除监测保护外还可预防传染性疾病
万兴播爆桌面端上线,支持AI数字人搜索、视频编辑等功能
2025“春晖杯”人工智能专场对接活动举办
一文读懂自动驾驶的激光雷达与视觉融合感知
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
零数科技CTO兰春嘉:区块链与人工智能的结合点在数据
苹果机器学习关键人物 Ali Farhadi 离职,回归 AI2 担任 CEO
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
人工智能时代 数字文明对话向“尼”走来
阿里达摩院发布免费开放100项AI专利许可的动机是什么?
中国移动主导创立元宇宙产业联盟,包括科大讯飞、芒果TV等在内,共24家成员
Midjourney创始人:AI应该成为人类思想的延伸
放弃自动驾驶,也是一种和解
鉴智机器人发布基于地平线征程5的标准视觉感知产品
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
BLIP-2、InstructBLIP稳居前三!十二大模型,十六份榜单,全面测评「多模态大语言模型」
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
游族AI创新院揭牌成立 推进AI赋能游戏业务
站在社会的高度理解人工智能
学而思推出AI第一课:基于自研大模型的AIGC课程
马斯克“揭秘”人工智能真面目
生成式AI对云运维的3大挑战
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品
微软和谷歌面临的人工智能困境:需要投入大量资金才能获得盈利
软通动力天枢元宇宙研究院签约落户江宁高新区
ChatGPT 可以设计机器人吗?
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

