


400 128 6709

行业新闻
 发布时间:2025-10-28
发布时间:2025-10-28 点击次数:
点击次数: hami 社区在 v2.7.0 版本中正式上线了面向 nvidia gpu 的 拓扑感知调度 功能。该功能旨在应对高性能计算(hpc)与 ai 大模型训练中的多卡通信瓶颈,通过智能任务调度机制,将计算负载精准部署到物理连接最优、通信延迟最低的 gpu 组合上,显著提升任务执行效率和集群整体算力利用率。本文将在介绍功能亮点的基础上,深入源码层面,全面解析 hami 实现 nvidia gpu 拓扑感知调度的设计思路与关键技术。
Fit 函数内置优化逻辑,针对不同类型的 GPU 请求——无论是多卡并行任务还是单卡独立任务——自动启用“最佳匹配”与“最小破坏”两种策略,兼顾短期性能最大化与长期资源可用性。HAMi 的拓扑感知调度机制遵循“先量化、再决策”的设计范式:首先在节点侧将复杂的硬件拓扑结构转化为标准化的数值评分;随后由调度系统结合这些评分做出最优分配决策。 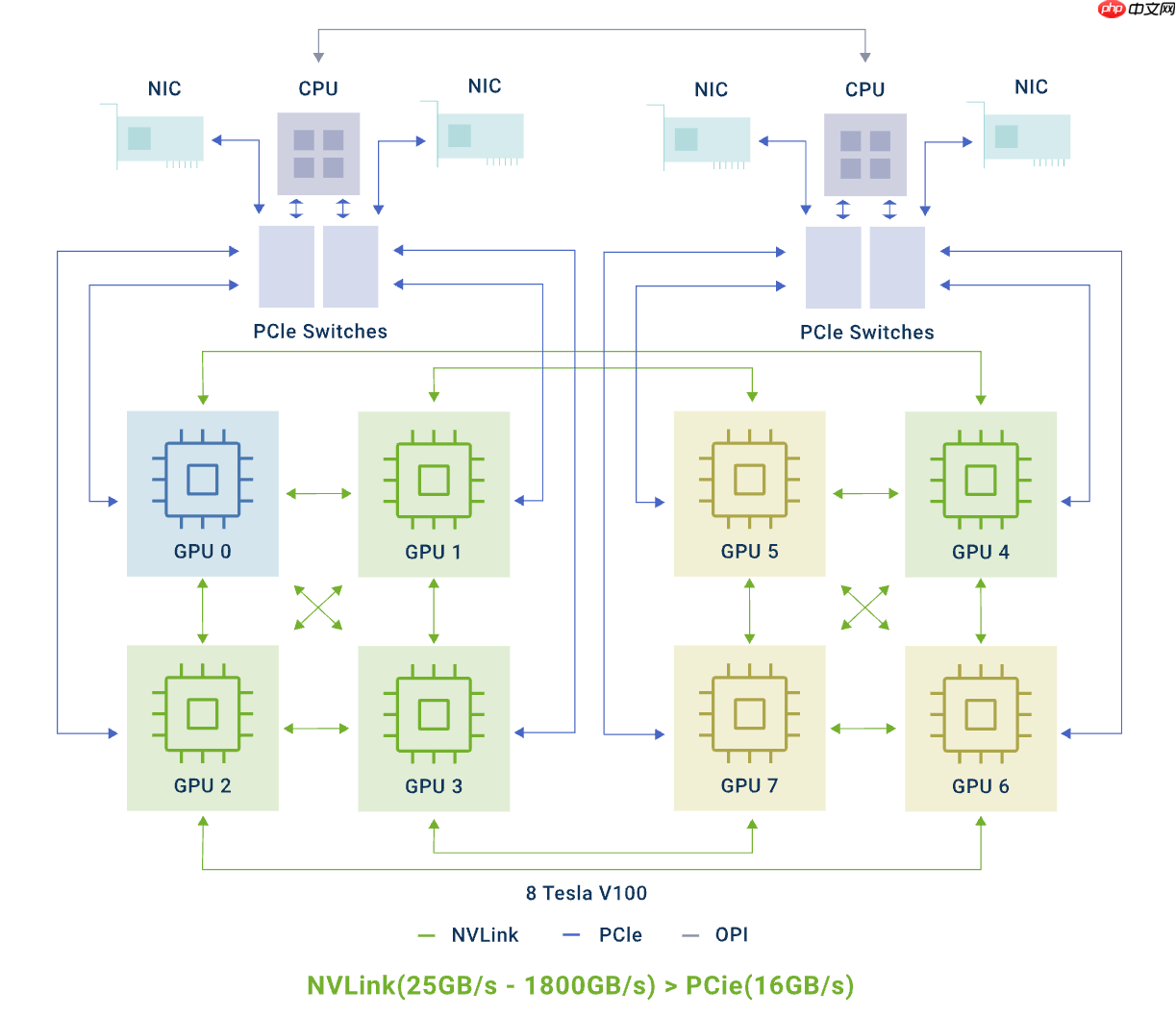 整个流程分为两个关键阶段:拓扑注册 和 调度决策。
整个流程分为两个关键阶段:拓扑注册 和 调度决策。
阶段一:拓扑注册 —— 将物理连接数字化
目标是将隐藏于硬件层的 GPU 互连关系,转换为软件可识别的数字指标。
SingleNVLINKLink 计 100 分,P2PLinkCrossCPU 计 10 分),算法遍历该图谱,为任意两块 GPU 之间生成一个综合通信能力得分。阶段二:调度决策 —— 智能选择最优设备组合
当调度器需要为 Pod 分配 GPU 资源时,会将请求转发给设备端的 Fit 函数,并携带当前节点的“通信分表”进行辅助判断。
Fit 函数首先排除不满足显存、算力等基础条件的 GPU。拓扑感知的核心在于准确捕捉设备间的真实连接状态,并将其转化为可参与调度决策的数值。整个过程由 Device Plugin 在本地完成。
拓扑图构建 ( build() function):
主要逻辑位于 pkg/device/nvidia/calculate_score.go 中的 build() 函数。它并非简单生成邻接矩阵,而是:
DeviceList,每个 Device 包含一个空的 Links 映射(map[int][]P2PLink)。(d1, d2),调用 GetP2PLink 与 GetNVLink(定义于 links.go)获取连接详情。P2PLink 结构体形式追加至对应设备的 Links 字段中,从而在内存中构建出完整的拓扑网络。通信分数计算 ( calculateGPUPairScore() function):
在拓扑图建立后,calculateGPUScore 调用 calculateGPUPairScore 将连接关系量化为具体分数。
switch 分支累加得分。例如:P2PLinkSameBoard 加 60 分,SingleNVLINKLink 加 100 分,TwoNVLINKLinks 加 200 分,最终返回总和作为两者通信质量评分。// File: pkg/device/nvidia/calculate_score.go
func (o *deviceListBuilder) build() (DeviceList, error) {
// ...
// 1. 初始化扁平化 DeviceList
var devices DeviceList
for i, d := range nvmlDevices {
// ... create device object ...
devices = append(devices, device)
}
// 2. 遍历并填充 Links map
for i, d1 := range nvmlDevices {
for j, d2 := range nvmlDevices {
if i != j {
// 获取并追加 P2P Link 信息
p2plink, _ := GetP2PLink(d1, d2)
devices[i].Links[j] = append(devices[i].Links[j], P2PLink{devices[j], p2plink})
<pre class="brush:php;toolbar:false;"> // 获取并追加 NVLink 信息
nvlink, _ := GetNVLink(d1, d2)
devices[i].Links[j] = append(devices[i].Links[j], P2PLink{devices[j], nvlink})
}
}
}
return devices, nil}
func calculateGPUPairScore(gpu0 Device, gpu1 Device) int { score := 0 for _, link := range gpu0.Links[gpu1.Index] { switch link.Type { case P2PLinkCrossCPU: score += 10 // ... (etc) ... case SingleNVLINKLink: score += 100 // ... (etc) ... } } return score }
核心调度逻辑实现在 pkg/device/nvidia/device.go 的 Fit() 函数中。当检测到启用了拓扑感知策略后,会根据请求的 GPU 数量切换不同的优化路径 。
。
// File: pkg/device/nvidia/device.go
func (nv *NvidiaGPUDevices) Fit(...) {
// ...
needTopology := util.GetGPUSchedulerPolicyByPod(device.GPUSchedulerPolicy, pod) == util.GPUSchedulerPolicyTopology.String()
// ...</p><pre class="brush:php;toolbar:false;"> // 过滤出符合资源要求的空闲 GPU (tmpDevs)
// ...
if needTopology {
if len(tmpDevs[k.Type]) > int(originReq) {
if originReq == 1 {
// 单卡任务:采用“最小破坏”策略
lowestDevices := computeWorstSignleCard(nodeInfo, request, tmpDevs)
tmpDevs[k.Type] = lowestDevices
} else {
// 多卡任务:采用“最佳匹配”策略
combinations := generateCombinations(request, tmpDevs)
combination := computeBestCombination(nodeInfo, combinations)
tmpDevs[k.Type] = combination
}
return true, tmpDevs, ""
}
}
// ...}
Fit 函数的整体调度流程如下图所示: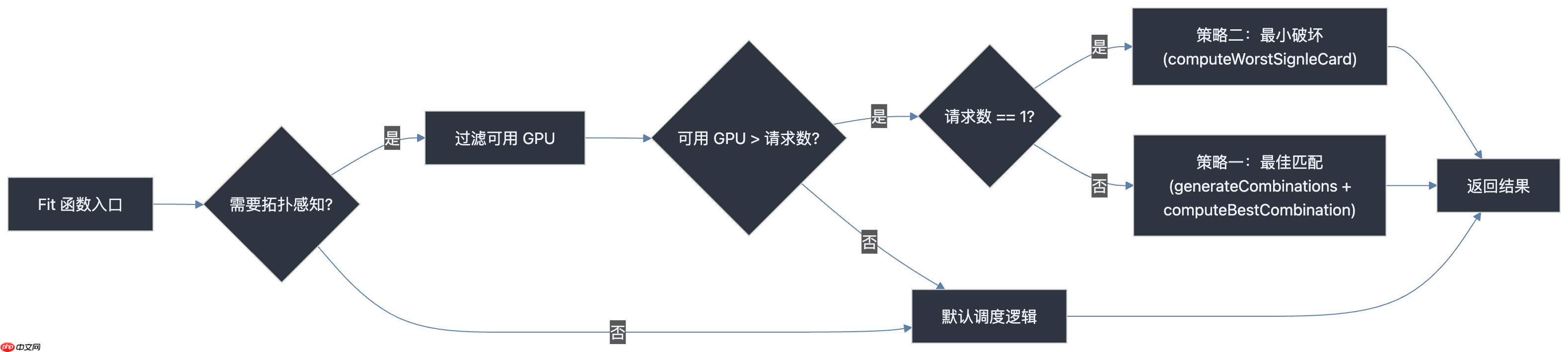
策略一:多卡任务 —— “最佳匹配”优先
 GoEnhance
GoEnhance
全能AI视频制作平台:通过GoEnhance AI让视频创作变得比以往任何时候都更简单。
 347
查看详情
347
查看详情

对于请求多个 GPU 的任务,目标是选出内部通信总分最高的设备组合。
generateCombinations 枚举所有可能的设备组合。computeBestCombination 遍历各组合,基于“通信分表”计算每组内所有设备对之间的分数总和。其核心逻辑示意图如下: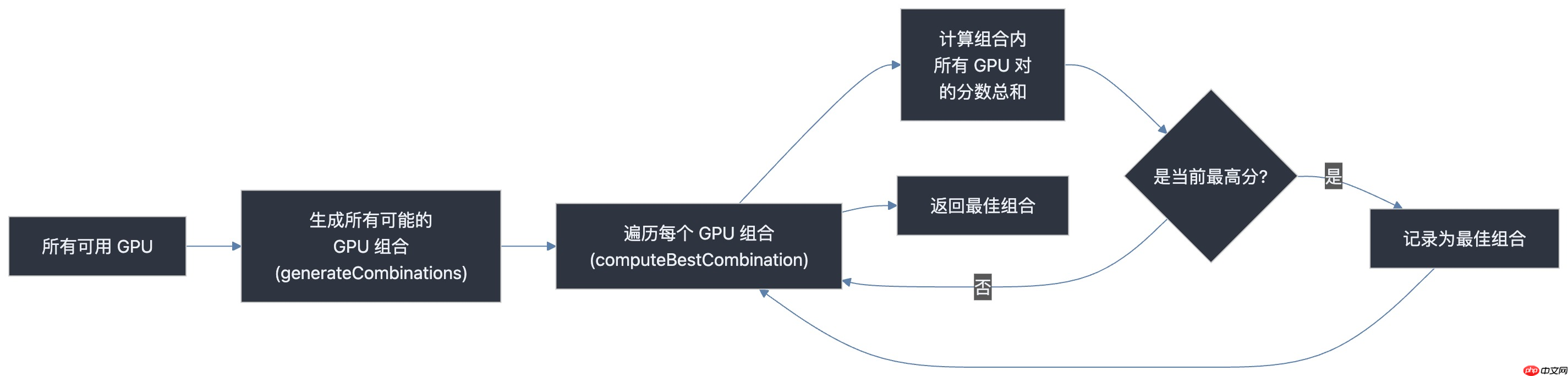
策略二:单卡任务 —— “最小破坏”优先
对于仅申请一块 GPU 的任务,策略转为保护整体拓扑完整性,避免占用关键连接节点。
computeWorstSignleCard 函数。其核心逻辑示意如下: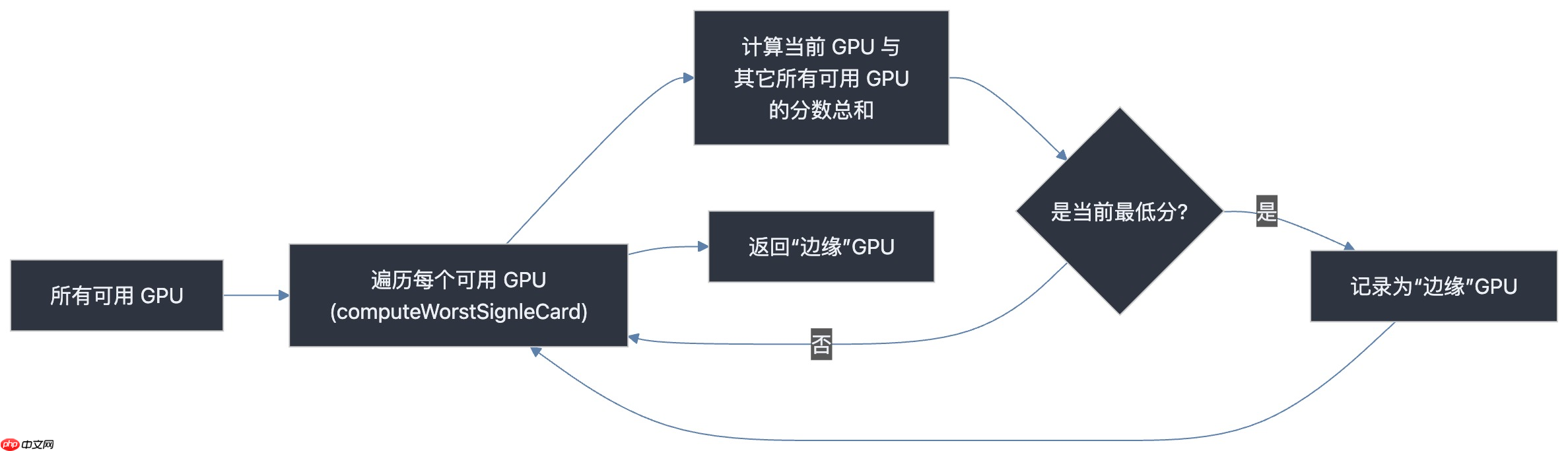
用户只需添加一条 Annotation 即可激活拓扑感知调度功能,系统将根据请求的 GPU 数量自动应用相应策略。
apiVersion: v1 kind: Pod metadata: name: gpu-topology-aware-job annotations:</p><h1>启用拓扑感知调度</h1><pre class="brush:php;toolbar:false;">hami.io/gpu-scheduler-policy: "topology-aware" # 系统将自动: # - 为多卡任务选择通信最优的 GPU 组合 # - 为单卡任务选择对拓扑影响最小的设备
spec: containers:
nvidia.com/gpu: "4"
HAMi 实现的 NVIDIA GPU 拓扑感知调度,展现了清晰而前瞻的工程设计理念:以动态感知替代静态配置,以全局优化取代局部贪心。设备端集成的双策略寻优算法,在消费预先计算的“通信分数”基础上,既保障了单个任务的极致性能表现,又维护了集群资源的长期可用性与调度灵活性。这一机制为云原生环境下大规模 AI 训练与科学计算任务提供了强有力的底层支持。
参考资料
再次诚挚感谢社区贡献者 @lengrongfu、@fyp711 对本特性的开发与推动!
以上就是【原理解析】HAMi × NVIDIA | GPU 拓扑感知调度实现详解的详细内容,更多请关注其它相关文章!
# node
# git
# 最优
# 遍历
# kubernete
# 大模型
# switch
# ai
# nvidia
# ubuntu
# app
# github
# go
# 东川区网络营销网络推广
# 安庆抖音营销推广招聘
# 电商网站建设源码
# 站外seo怎么促进收录
# 1688网站的推广流程
# 提升网站优化排行一览
# 东胜网站建设哪家好
# 贵州seo软件怎么装
# 网页设计网站建设重庆
# 淡水网站推广公司
# 这一
# 检测到
# 开源
# 拓扑图
# 可用性
# 基础上
# 链路
# 转化为
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
旷视入选北京市通用人工智能产业创新伙伴计划
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
插画师对AI绘画软件的态度是怎样的?
微软Xbox称VR和AR还需要时间 先玩大的
AYANEO 安卓掌机 Pocket AIR 配置公布:天玑 1200 + 5.5 英寸屏
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
云鲸发布全新的扫拖机器人J4系列
通用医疗人工智能如何革新医疗行业?
从医疗康复外骨骼到通用人形机器人,傅利叶智能推动核心技术升级
特斯拉首发人形机器人“擎天柱”亮相世界人工智能大会
AI无法对传统文化符号进行解构和创新
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
人工智能自己玩自己
央广车联网亮相2025世界人工智能大会
2025 年开发者必须知道的六个 AI 工具
一文看懂被英伟达看中的九号机器人移动底盘
鸿蒙生态带来了哪些新的流量可能性,包括AI、服务分发和原生智能等方面?
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
华为即将推出HarmonyOS 4,再度领先行业的AI技术
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
笔神作文声讨学而思AI大模型 称用“爬虫”技术盗取数据
亚马逊确认今年不举办re:MARS人工智能大会
视觉中国宣布推出AI灵感绘图、画面扩展功能
普林斯顿大学推出 Infinigen AI 模型,生成真实自然环境 3D 场景
成功孵化首个大型模型解决方案的重庆人工智能创新中心
OpenAI 静默关闭 AI 文本检测工具,准确率仅为 26%
Meta发布"类人"AI图像创建模型,能解决多出手指等Bug
复旦发布「新闻推荐生态系统模拟器」SimuLine:单机支持万名读者、千名创作者、100+轮次推荐
Bing 聊天机器人现支持在桌面端用语音提问
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
人工智能在商业中的风险和局限性
当TS遇上AI,会发生什么?
大型无人机FH-98国内首次夜航转场成功
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
借力AI!PCB全球巨头,有爆发潜质吗?
如何用Transformer BEV克服自动驾驶的极端情况?
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA
利亚德加码AI战略,与光年无限图灵机器人全面开展AI研发业务合作
华为余承东表示:鸿蒙可能拥有强大的人工智能大模型能力
谷歌将使用公开信息训练 AI 模型,构建更强大的自家产品
Meta将VR头显最低年龄限制从13岁降至10岁
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
速途网络成立“人工智能专家委员会”5位中美博士加盟
“长沙造”无人机,领先的不止植保
选对AI智能写作软件,让创作游刃有余!
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

