


400 128 6709

行业新闻
 发布时间:2025-08-01
发布时间:2025-08-01 点击次数:
点击次数: 本文介绍基于PaddleClas实现的Shunt Transformer,针对ViT感受野局限,提出shunted self-attention获取多尺度信息,结合特定前馈层增强联系。转换PyTorch权重后,在ImageNet-1k验证,shunt_s和shunt_b精度接近原结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

paper:Shunted Self-Attention via Multi-Scale Token Aggregation
github:https://github.com/OliverRensu/Shunted-Transformer
ViT模型在设计时有个特点:在相同的层中每个token的感受野相同。这限制了self-attention层捕获多尺度特征的能力,从而导致处理多尺度目标的图片时性能下降。针对这个问题,作者提出了shunted self-attention,使得每个attention层可以获取多尺度信息。
本项目使用PaddleClas实现Shunt Transformer组网,并且将官方提供的pytorch权重转换为PaddlePaddle权重,在ImageNet-1k 验证集测试其精度。
本篇论文的核心是提出了Shunted Self-Attention,几种不同的ViT模块对比如下:
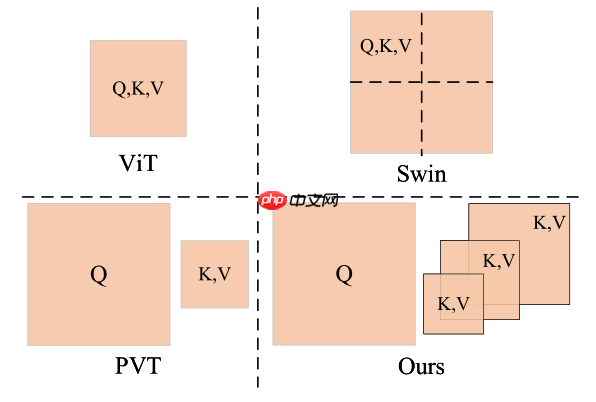
ViT: QKV维度相同,可以得到全局感受野但是计算量大
Swin:划分window,self-attention在窗口内计算减少计算量,同时引入shift操作使得感受野增加
PVT:降低KV的patch数量来降低计算量
shunted Self-Attention:在单个attention层计算时得到多尺度KV,再计算Self-Attention
计算过程如下:
上式中,i表示KV尺度的个数,MTA(multi-scale token aggregation)表示下采样率为ri的特征聚合模块(通过带步长的卷积实现),LE是深度可分离卷积层,用来增强V中相邻像素的联系。
 Openflow
Openflow
一键极速绘图,赋能行业工作流
 88
查看详情
88
查看详情

实现代码:
class Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__() assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio if sr_ratio > 1:
self.act = nn.GELU() if sr_ratio==8:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=8, stride=8)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=4, stride=4)
self.norm2 = nn.LayerNorm(dim) if sr_ratio==4:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=4, stride=4)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=2, stride=2)
self.norm2 = nn.LayerNorm(dim) if sr_ratio==2:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=2, stride=2)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=1, stride=1)
self.norm2 = nn.LayerNorm(dim)
self.kv1 = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.local_conv1 = nn.Conv2D(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2)
self.local_conv2 = nn.Conv2D(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2) else:
self.kv = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.local_conv = nn.Conv2D(dim, dim, kernel_size=3, padding=1, stride=1, groups=dim)
self.apply(self._init_weights) def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape([B, N, self.num_heads, C // self.num_heads]).transpose([0, 2, 1, 3]) if self.sr_ratio > 1:
x_ = x.transpose([0, 2, 1]).reshape([B, C, H, W])
x_1 = self.act(self.norm1(self.sr1(x_).reshape([B, C, -1]).transpose([0, 2, 1])))
x_2 = self.act(self.norm2(self.sr2(x_).reshape([B, C, -1]).transpose([0, 2, 1])))
kv1 = self.kv1(x_1).reshape([B, -1, 2, self.num_heads//2, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
kv2 = self.kv2(x_2).reshape([B, -1, 2, self.num_heads//2, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k1, v1 = kv1[0], kv1[1] #B head N C
k2, v2 = kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
在MLP中加入了Detail Specific分支(depth-wise卷积)来增强相邻像素的联系,与PVT的MLP不同是有了残差连接。
PS:源码中GELU的位置和残差连接的位置顺序与图相反,参考下方代码。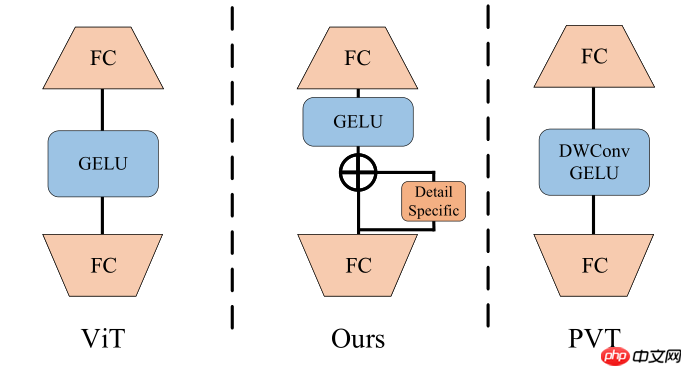
代码如下:
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x, H, W):
x = self.fc1(x)
x = self.act(x + self.dwconv(x, H, W)) # 残差连接,这里和图画的顺序不一样,图应该画错了
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim) def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2) return x
网络结构如图所示,整体结构与大部分模型相同,区别在于内部的Transfmer block做出了上述改进,此外,该网络未使用cls_token和pos_embedding。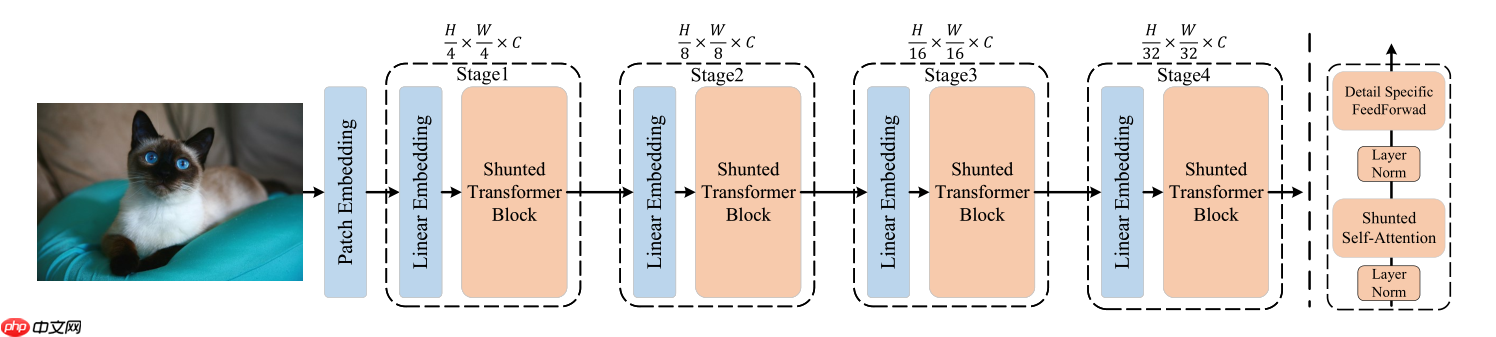
在ImageNet-1k上表现如下: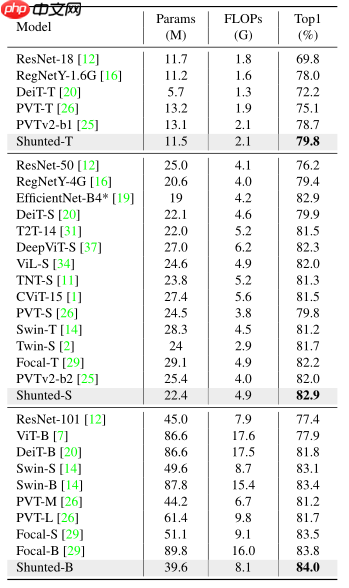
使用paddleclas组网,并将官方repo提供的shunt_s和shunt_b权重由pytorch转换为paddle,在iamgenet-1k上验证其效果,结果如下表:
| 模型 | 分辨率 | acc-top1(torch) | acc_top1(paddle) |
|---|---|---|---|
| shunt_t | 224x224 | 79.8% | 官方未提供权重 |
| shunt_s | 224x224 | 82.9% | 82.87% |
| shunt_b | 224x224 | 84.0% | 83.826% |
# step 1: tar dataset%cd ~/ !mkdir ~/data/data96753/val !tar -xf ~/data/data96753/ILSVRC2012_img_val.tar -C ~/data/data96753/valIn [ ]
# step 2: unzip weight%cd ~/data/data139670/ !unzip -oq shunt_weight.zipIn [ ]
# step 3: ImageNet-1K val shunt_s%cd ~/PaddleClas/
!python3 tools/eval.py -c ./ppcls/configs/ImageNet/shunt/shunt_s.yaml \
-o Global.pretrained_model=/home/aistudio/data/data139670/shunt_s
In [ ]
# step 3: ImageNet-1K val shunt_b%cd ~/PaddleClas/
!python3 tools/eval.py -c ./ppcls/configs/ImageNet/shunt/shunt_b.yaml \
-o Global.pretrained_model=/home/aistudio/data/data139670/shunt_b
以上就是Shunted Transformer 飞桨权重迁移体验的详细内容,更多请关注其它相关文章!
# git
# python
# 导航推广营销案例
# 沙漠骆驼视频网站建设
# 开封抖音推广营销招聘网
# 免费网站推广系统
# 亚马逊黑科技操纵关键词排名
# seo图片命名技巧
# 付陶seo
# 上海网站优化推广找哪家
# 金华网站建站建设
# 网站推广怎么避免流失
# 相关文章
# 这个问题
# 工作流
# 出了
# 有个
# 官网
# 转换为
# 提出了
# 一言
# 中文网
# fig
# latte
# udio
# igs
# 区别
# ai
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
智能手机应用中的人工智能的重要性
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
深度学习模型综述:用于3D MRI和CT扫描的应用
360发布数字安全和人工智能的强大结合:360安全大模型
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
当一切设备都受到人工智能的控制
鉴智机器人发布基于地平线征程5的标准视觉感知产品
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会
你大脑中的画面,现在可以高清还原了
视觉中国宣布推出AI灵感绘图、画面扩展功能
曝索尼在开发新头显设备:游戏中使用AR技术
OpenAI 引入个性化指令功能,消除对话中的重复偏好与信息
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
数字彩排、虚拟建厂!这家顶级洗衣机工厂敲开“工业元宇宙”之门
找对了风口想不火都难,乐天派机器人,安卓机器人的最终形态?
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
百度举办AIGC创作沙龙,现场传授AI绘画“咒语”技巧
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
对话式论文阅读工具PaperMate上线,综述细节AI告诉你
国内通用人形机器人将发布、产业加速突破
智能客服进入AI 2.0时代 容联云发布语言大模型“赤兔”
13 个提高生产力的 AI 工具
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
CREATOR制造、使用工具,实现LLM「自我进化」
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
微软为 AI 初学者推出免费网课:为期 12 周,共 24 节课
人工智能改变网络安全和用户体验的三种方式
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
参考封面|人工智能“淘金热”
如何利用物联网技术提高企业生产线智能化水平,提升生产效率
破解零碳产业园建设规范和成果评价难题
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
利好来了,AI再起一波?
美图秀秀发布7款AI产品:支持用户创作、商业创作
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
LinkedIn 推出生成式 AI 辅助撰写帖文功能,将向所有用户开放
构建AI绘画网站的方法:使用API接口和调用步骤
全新“AI助手”!讯飞星火助手中心人机协作共创新生态
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
生成式人工智能如何改变云安全的游戏规则
国内首款大尺寸仿鸵双足机器人“大圣”亮相,穿戴红色战袍
Meta Connect 2025已确定时间为9月27-28,主题涵盖Quest 3与AI技术
北京公司实施AI技术,推行4.5天工作制,抵制996文化,提升员工工作幸福感
“直击”AI新世界,智能机器人再次“火出圈”了
生活垃圾智能分类机器人社区展“才能”,征求居民意见
探展WAIC | 第四范式“式说”聚焦toB大模型,布局生成式AI重构企业软件
 当前位置:
当前位置:  kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x 上一篇:
上一篇: 返回列表
返回列表

