


400 128 6709

行业新闻
 发布时间:2023-07-06
发布时间:2023-07-06 点击次数:
点击次数: 近几年,图像生成领域取得了巨大的进步,尤其是文本到图像生成方面取得了重大突破:只要我们用文本描述自己的想法,AI 就能生成新奇又逼真的图像。
但其实我们可以更进一步 —— 将头脑中的想法转化为文本这一步可以省去,直接通过脑活动(如 EEG(脑电图)记录)来控制图像的生成创作。
这种「思维到图像」的生成方式有着广阔的应用前景。例如,它能极大提高艺术创作的效率,并帮助人们捕捉稍纵即逝的灵感;它也有可能将人们夜晚的梦境进行可视化;它甚至可能用于心理治疗,帮助自闭症儿童和语言障碍患者。
最近,来自清华大学深圳国际研究生院、腾讯 AI Lab 和鹏城实验室的研究者们联合发表了一篇「思维到图像」的研究论文,利用预训练的文本到图像模型(比如 Stable Diffusion)强大的生成能力,直接从脑电图信号生成了高质量的图像。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/pdf/2306.16934.pdf
项目地址:https://github.com/bbaaii/DreamDiffusion
 Android 应用框架原理与程序设计36技pdf繁体版
Android 应用框架原理与程序设计36技pdf繁体版
Android应用框架原理与程序设计36技 pdf繁体版,书籍内容适用于Android 1.0,有些朋友可能对Android还不太熟悉吧?不知您是否听说过Google 在HTC定制的高端手机呢?其操作系统是基于Android的,如果还是不太清楚的话,可以Google一下“HTC g2”手机,可以大致了解一下手机操作系统的界面及架构特点。不管怎么说,Android手机编程目前还是主要面向高端,在将来可能会普及,因此Android编程还是很有必要掌握的。
 0
查看详情
0
查看详情

近期一些相关研究(例如 MinD-Vis)尝试基于 fMRI(功能性磁共振成像信号)来重建视觉信息。他们已经证明了利用脑活动重建高质量结果的可行性。然而,这些方法与理想中使用脑信号进行快捷、高效的创作还差得太远,这主要有两点原因:
首先,fMRI 设备不便携,并且需要专业人员操作,因此捕捉 fMRI 信号很困难;
其次,fMRI 数据采集的成本较高,这在实际的艺术创作中会很大程度地阻碍该方法的使用。
相比之下,EEG 是一种无创、低成本的脑电活动记录方法,并且现在市面上已经有获得 EEG 信号的便携商用产品。
但实现「思维到图像」的生成还面临两个主要挑战:
1)EEG 信号通过非侵入式的方法来捕捉,因此它本质上是有噪声的。此外,EEG 数据有限,个体差异不容忽视。那么,如何从如此多的约束条件下的脑电信号中获得有效且稳健的语义表征呢?
2)由于使用了 CLIP 并在大量文本 - 图像对上进行训练,Stable Diffusion 中的文本和图像空间对齐良好。然而,EEG 信号具有其自身的特点,其空间与文本和图像大不相同。如何在有限且带有噪声的 EEG - 图像对上对齐 EEG、文本和图像空间?
为了解决第一个挑战,该研究提出,使用大量的 EEG 数据来训练 EEG 表征,而不是仅用罕见的 EEG 图像对。该研究采用掩码信号建模的方法,根据上下文线索预测缺失的 token。
不同于将输入视为二维图像并屏蔽空间信息的 MAE 和 MinD-Vis,该研究考虑了 EEG 信号的时间特性,并深入挖掘人类大脑时序变化背后的语义。该研究随机屏蔽了一部分 token,然后在时间域内重建这些被屏蔽的 token。通过这种方式,预训练的编码器能够对不同个体和不同脑活动的 EEG 数据进行深入理解。
对于第二个挑战,先前的解决方法通常直接对 Stable Diffusion 模型进行微调,使用少量噪声数据对进行训练。然而,仅通过最终的图像重构损失对 SD 进行端到端微调,很难学习到脑信号(例如 EEG 和 fMRI)与文本空间之间的准确对齐。因此,研究团队提出采用额外的 CLIP 监督,帮助实现 EEG、文本和图像空间的对齐。
具体而言,SD 本身使用 CLIP 的文本编码器来生成文本嵌入,这与之前阶段的掩码预训练 EEG 嵌入非常不同。利用 CLIP 的图像编码器提取丰富的图像嵌入,这些嵌入与 CLIP 的文本嵌入很好地对齐。然后,这些 CLIP 图像嵌入被用于进一步优化 EEG 嵌入表征。因此,经过改进的 EEG 特征嵌入可以与 CLIP 的图像和文本嵌入很好地对齐,并更适合于 SD 图像生成,从而提高生成图像的质量。
基于以上两个精心设计的方案,该研究提出了新方法 DreamDiffusion。DreamDiffusion 能够从脑电图(EEG)信号中生成高质量且逼真的图像。
 图片
图片
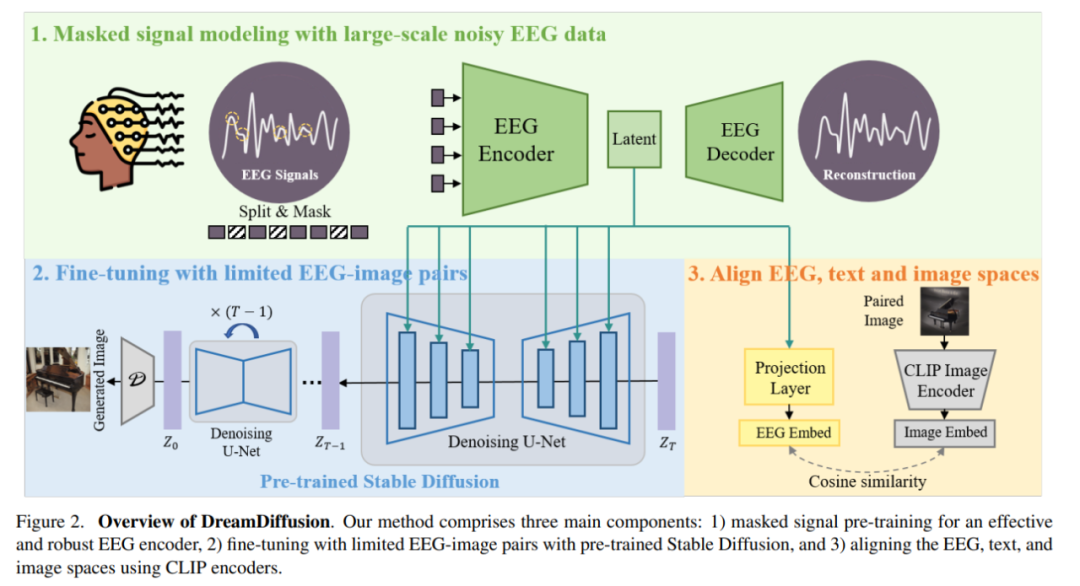
具体来说,DreamDiffusion 主要由三个部分组成:
1)掩码信号预训练,以实现有效和稳健的 EEG 编码器;
2)使用预训练的 Stable Diffusion 和有限的 EEG 图像对进行微调;
3)使用 CLIP 编码器,对齐 EEG、文本和图像空间。
首先,研究人员利用带有大量噪声的 EEG 数据,采用掩码信号建模,训练 EEG 编码器,提取上下文知识。然后,得到的 EEG 编码器通过交叉注意力机制被用来为 Stable Diffusion 提供条件特征。
 图片
图片
为了增强 EEG 特征与 Stable Diffusion 的兼容性,研究人员进一步通过在微调过程中减少 EEG 嵌入与 CLIP 图像嵌入之间的距离,进一步对齐了 EEG、文本和图像的嵌入空间。
与 Brain2Image 对比
研究人员将本文方法与 Brain2Image 进行比较。Brain2Image 采用传统的生成模型,即变分自编码器(VAE)和生成对抗网络(GAN),用于实现从 EEG 到图像的转换。然而,Brain2Image 仅提供了少数类别的结果,并没有提供参考实现。
鉴于此,该研究对 Brain2Image 论文中展示的几个类别(即飞机、南瓜灯和熊猫)进行了定性比较。为确保比较公平,研究人员采用了与 Brain2Image 论文中所述相同的评估策略,并在下图 5 中展示了不同方法生成的结果。
下图第一行展示了 Brain2Image 生成的结果,最后一行是研究人员提出的方法 DreamDiffusion 生成的。可以看到 DreamDiffusion 生成的图像质量明显高于 Brain2Image 生成的图像,这也验证了本文方法的有效性。
 图片
图片
消融实验
预训练的作用:为了证明大规模 EEG 数据预训练的有效性,该研究使用未经训练的编码器来训练多个模型进行验证。其中一个模型与完整模型相同,而另一个模型只有两层的 EEG 编码层,以避免数据过拟合。在训练过程中,这两个模型分别进行了有 / 无 CLIP 监督的训练,结果如表 1 中 Model 列的 1 到 4 所示。可以看到,没有经过预训练的模型准确性有所降低。
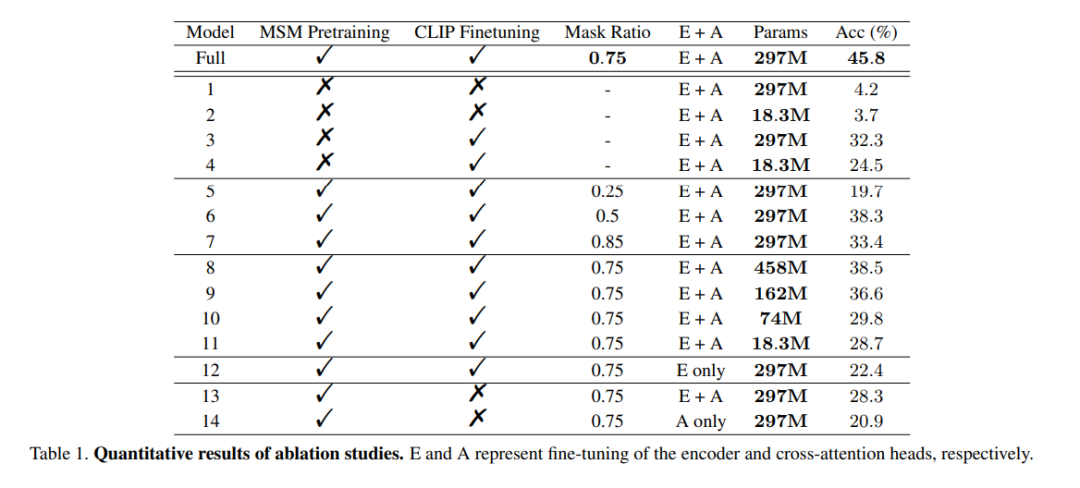
mask ratio:本文还研究了用 EEG 数据确定 MSM 预训练的最佳掩码比。如表 1 中的 Model 列的 5 到 7 所示,过高或过低的掩码比会对模型性能都会产生不利影响。当掩码比为 0.75 达到最高的整体准确率。这一发现至关重要,因为这表明,与通常使用低掩码比的自然语言处理不同,在对 EEG 进行 MSM 时,高掩码比是一个较好的选择。
CLIP 对齐:该方法的关键之一是通过 CLIP 编码器将 EEG 表征与图像对齐。该研究进行实验验证了这种方法的有效性,结果如表 1 所示。可以观察到,当没有使用 CLIP 监督时,模型的性能明显下降。实际上,如图 6 右下角所示,即使在没有预训练的情况下,使用 CLIP 对齐 EEG 特征仍然可以得到合理的结果,这凸显了 CLIP 监督在该方法中的重要性。
 图片
图片
以上就是你大脑中的画面,现在可以高清还原了的详细内容,更多请关注其它相关文章!
# ai
# stable diffusion
# 脑中
# 掩码
# 程序设计
# 所示
# 创意
# 成都seo优化工作
# 嘉兴搜索营销推广
# 成都外贸网站建设价钱
# 荥阳seo排名优化
# 童装怎么营销主题推广语
# 江苏网站建设口碑推荐
# 营销型微博手机推广
# 美剧seo
# SEO 秘籍
# 成都建设网站公司
# 并在
# 重构
# 不太
# 很好
# 万元
# 高质量
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
建立元宇宙产业联盟:移动、咪咕、华为、小米等加入
ChatGPT 可以设计机器人吗?
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
2025世界人工智能大会(上海)开幕式纪要
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
国网辉南供电:无人机空中巡检 全力护航端午佳节
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
一图速览 | 十大脑机接口关键技术发布
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
超级智能到底是什么?
即时 AI再次升级 30秒生成自带动效的网页 生成速度提升100%
国内首款大尺寸仿鸵双足机器人“大圣”亮相,穿戴红色战袍
小红书陷入麻烦!被指控未经许可使用用户图片进行AI训练
深剖Apple Vision Pro中暗藏的“AI”
人工智能在重症监护室的未来
苹果AR头显商标与华为撞车,在中国或改名
猿编程参加人工智能高峰论坛,推动人工智能教育解决方案在千所学校推行
时隔 4 年:谷歌更新安卓机器人 LOGO,形象更立体
AI技术改变*,新骗局来袭,*成功率接近100%
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
这效果能打几分?AI真人化《名侦探柯南》
V社回应拒绝上架含 AI 生成内容的游戏:审核政策正在调整中
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
“黑科技”亮相大湾区轨交论坛 智慧交通迈向“强AI”
下一个前沿:量子机器学习和人工智能的未来
人工智能如何帮助制造业?
AI工具助力公司实施每周4.5天工作制,带来巨大效益
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
自然语言生成在智能家居设备中的应用
人形机器人概念集体爆发,能买吗?
生活垃圾智能分类机器人社区展“才能”,征求居民意见
华为即将推出HarmonyOS 4,再度领先行业的AI技术
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
报告称 70% 程序员已使用各种 AI 工具编程
工业机器人及非标自动化设备集成服务提供商
杭州举办第19届亚运会,主题为「亚运元宇宙」的发布仪式举行
学生作文评分的新趋势:教师与AI的合作模式
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
PHP和OpenCV库:如何实现人脸识别
全球首款AI裸眼3D平板 国产的售价破万
AYANEO 安卓掌机 Pocket AIR 配置公布:天玑 1200 + 5.5 英寸屏
AI证件照生成器:实际测试中AI软件展现了绝无仅有的强大效能
将上下文长度扩展到256k,无限上下文版本的LongLLaMA来了?
游族AI创新院揭牌成立 推进AI赋能游戏业务
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
人工智能行业急缺人 AI人才年薪能达近42万元
Vision Pro 太贵,苹果基于 iPhone 的 VR 头显专利曝光
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

