


400 128 6709

行业新闻
 发布时间:2023-07-03
发布时间:2023-07-03 点击次数:
点击次数: 2025 年 12 月发布的 CPM-1 是国内首个中文大模型 ;2025 年 9 月发布的 CPM-Ant 仅微调 0.06% 参数就能超越全参数微调效果;2025 年 5 月发布的 WebCPM 是 中文首个基于搜索的问答开源模型。CPM-Bee 百亿大模型是团队最新发布的基座模型,中文能力登顶权威榜单 ZeroCLUE,英文能力打平 LLaMA。
屡屡作出破壁性成就,CPM 系列大模型一直在引领国产大模型攀登高峰,最近发布的 VisCPM 是又一次证明!VisCPM 是由面壁智能、清华大学 NLP 实验室和知乎联合开源在 OpenBMB 的多模态大模型系列,其中 VisCPM-Chat 模型支持中英双语的多模态对话能力,VisCPM-Paint 模型支持文到图生成能力,评测显示 VisCPM 在中文多模态开源模型中达到最佳水平。
VisCPM 基于百亿参数基座模型 CPM-Bee 训练,融合视觉编码器(Q-Former 和视觉解码器(Diffusion-UNet)以支持视觉信号的输入和输出。得益于 CPM-Bee 底座优秀的双语能力,VisCPM 可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 VisCPM简易架构图
VisCPM简易架构图
我们来详细看看 VisCPM-Chat 和 VisCPM-Paint 到底牛在哪里。
 图片
图片
viscpm 链接:https://github.com/openbmb/viscpm
 ChatGPT Writer
ChatGPT Writer
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。
 106
查看详情
106
查看详情

VisCPM-Chat 支持面向图像进行中英双语多模态对话。该模型使用 Q-Former 作为视觉编码器,使用 CPM-Bee(10B)作为语言交互基底模型,并通过语言建模训练目标融合视觉和语言模型。模型训练包括预训练和指令精调两阶段。
团队使用约 100M 高质量英文图文对数据 对 VisCPM-Chat 进行了预训练,数据包括 CC3M、CC12M、COCO、Visual Genome、Laion 等。在预训练阶段,语言模型参数保持固定,仅更新 Q-Former 部分参数,以支持大规模视觉 - 语言表示的高效对齐。
之后团队对 VisCPM-Chat 进行了指令精调,采用 LLaVA-150K 英文指令精调数据,并混合相应翻译后的中文数据对模型进行指令精调,以对齐模型多模态基础能力和用户使用意图。在指令精调阶段,他们更新了全部模型参数,以提升指令精调数据的利用效率。
有趣的是,团队发现即使仅采用英文指令数据进行指令精调,模型也可以理解中文问题,但仅能用英文回答。这表明模型的多语言多模态能力已经得到良好的泛化。在指令精调阶段进一步加入少量中文翻译数据,就可以将模型回复语言和用户问题语言对齐。
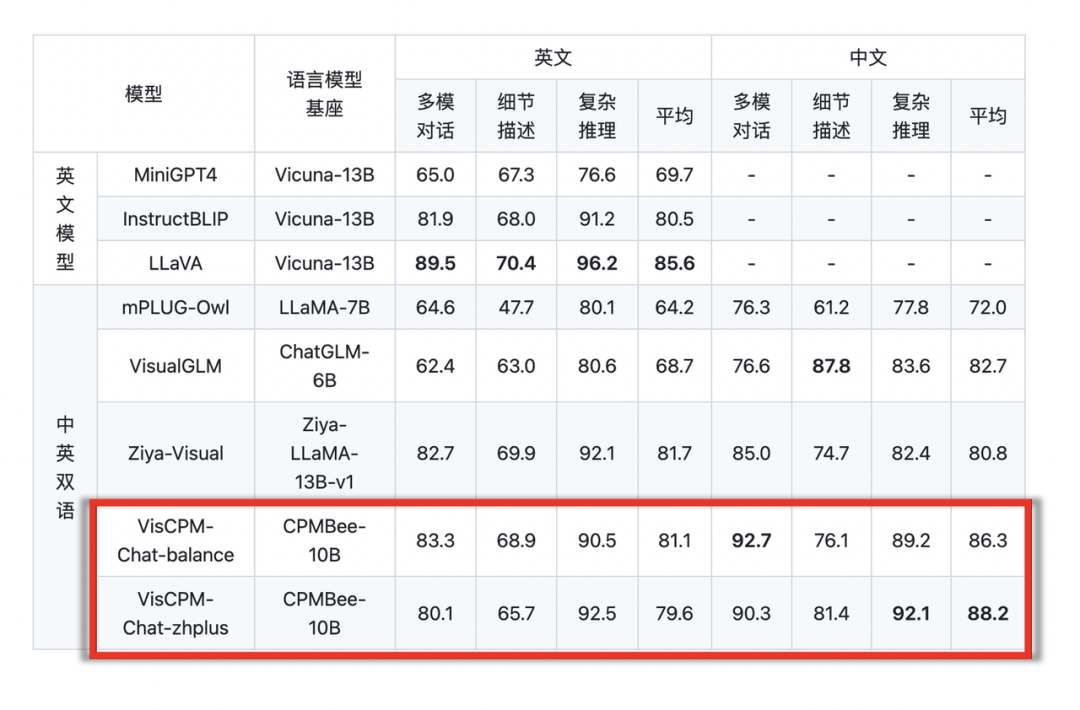
团队在 LLaVA 英文测试集和翻译的中文测试集对模型进行了评测,该评测基准考察模型在开放域对话、图像细节描述、复杂推理方面的表现,并使用 GPT-4 进行打分。可以观察到,VisCPM-Chat 在中文多模态能力方面取得了最佳的平均性能,在通用域对话和复杂推理上表现出色,同时也表现出了不错的英文多模态能力。
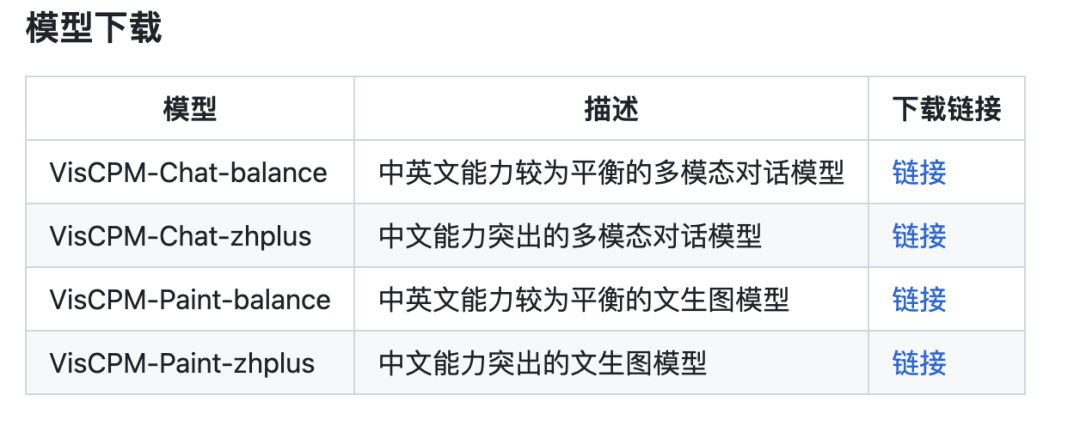
VisCPM-Chat 提供了两个模型版本,分别为 VisCPM-Chat-balance 和 VisCPM-Chat-zhplus,前者在英文和中文两种语言上的能力较为平衡,后者在中文能力上更加突出。两个模型在指令精调阶段使用的数据相同,VisCPM-Chat-zhplus 在预训练阶段额外加入了 20M 清洗后的原生中文图文对数据和 120M 翻译到中文的图文对数据。
 图片
图片
下面是 VisCPM-Chat 的多模态对话能力展示,不仅能识别具体地区的地图,还能读懂涂鸦画和电影海报,甚至认识星巴克的 logo。而且,中英文双语都很溜!

再来看 VisCPM-Paint ,它支持中英双语的文到图生成。该模型使用 CPM-Bee(10B)作为文本编码器,使用 UNet 作为图像解码器,并通过扩散模型训练目标融合语言和视觉模型。
在训练过程中,语言模型参数始终保持固定。使用 Stable Diffusion 2.1 的 UNet 参数初始化视觉解码器,并通过逐步解冻其中关键的桥接参数将其与语言模型融合:首先训练文本表示映射到视觉模型的线性层,然后进一步解冻 UNet 的交叉注意力层。该模型在 Laion 2B 英文图文对数据上进行了训练。
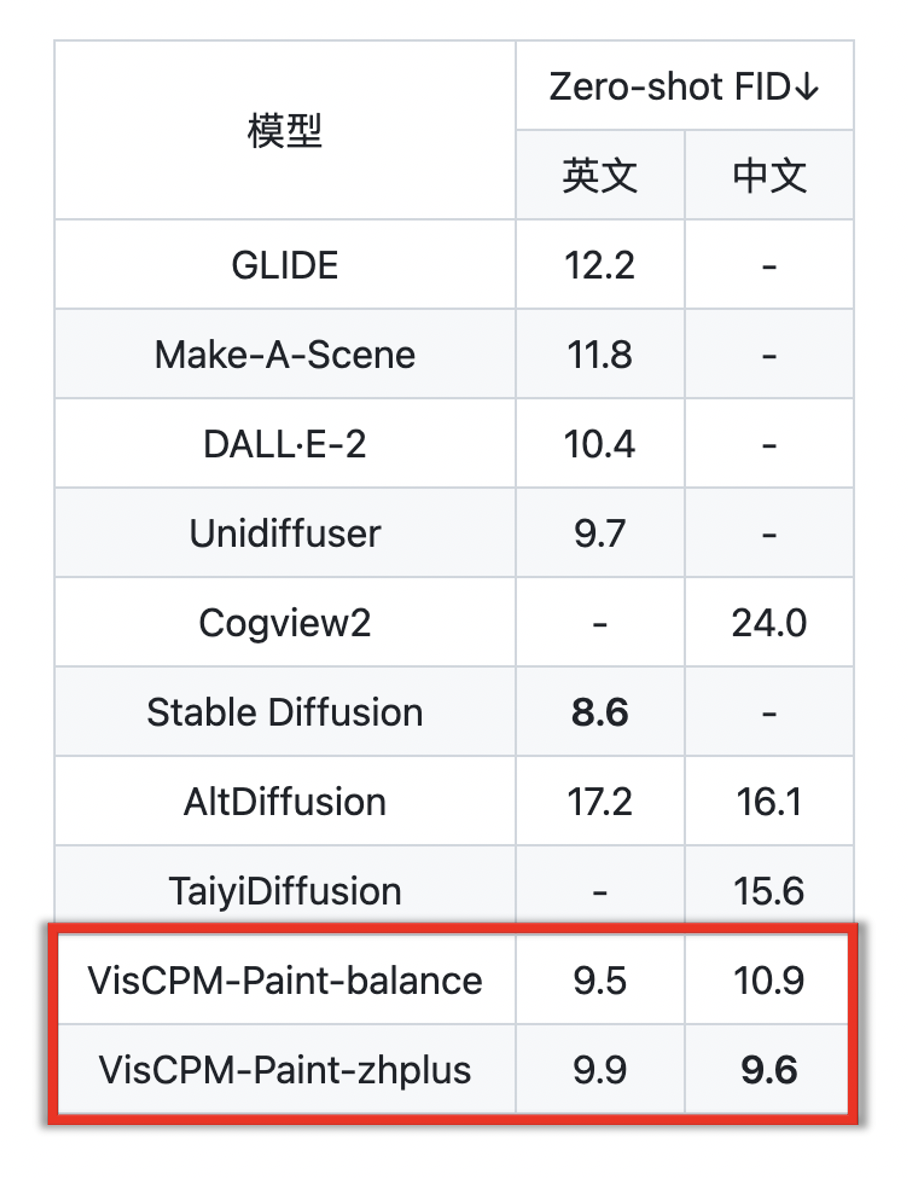
与 VisCPM-Paint 类似,得益于基座模型 CPM-Bee 的双语能力,VisCPM-Paint 可以仅通过英文图文对训练,泛化实现良好的中文文到图生成能力,达到中文开源模型的最佳效果。通过进一步加入 20M 清洗后的原生中文图文对数据,以及 120M 翻译到中文的图文对数据,模型的中文文到图生成能力获得进一步提升。同样,VisCPM-Paint 有 balance 和 zhplus 两个不同的版本。他们在标准图像生成测试集 MSCOCO 上采样了 3 万张图片,计算了常用评估图像生成指标 FID (Fréchet Inception Distance) 评估生成图片的质量。
VisCPM-Paint 模型中分别输入 “海上生明月,天涯共此时,唯美风格,抽象风格”“人闲桂花落,月静春山空” 两条 prompts,生成了以下两张图片:

(生成效果稳定性仍有提升空间)
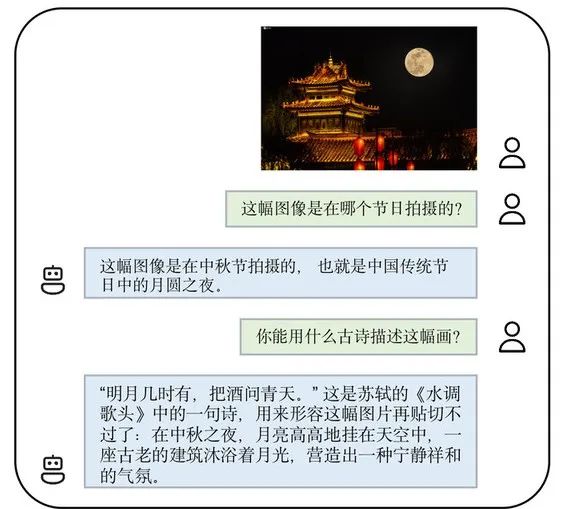
相当惊艳,可以说精准把握了古诗词的意境,以后读不懂诗句就直接生成个图片来理解!如果应用在设计上,可以节省一大笔人力。不仅能 “作画”,用上 VisCPM-Chat,还能 “吟诗”:用图片反向检索诗句。比如能用李白的诗描绘黄河的景象并作解读,在面对中秋月夜时还能用苏轼的《水调歌头》借景抒情。

VisCPM 不仅生成效果好,下载版本设计考虑周到,安装和使用也十分简易。 
 VisCPM提供不同中英文能力的版本
VisCPM提供不同中英文能力的版本
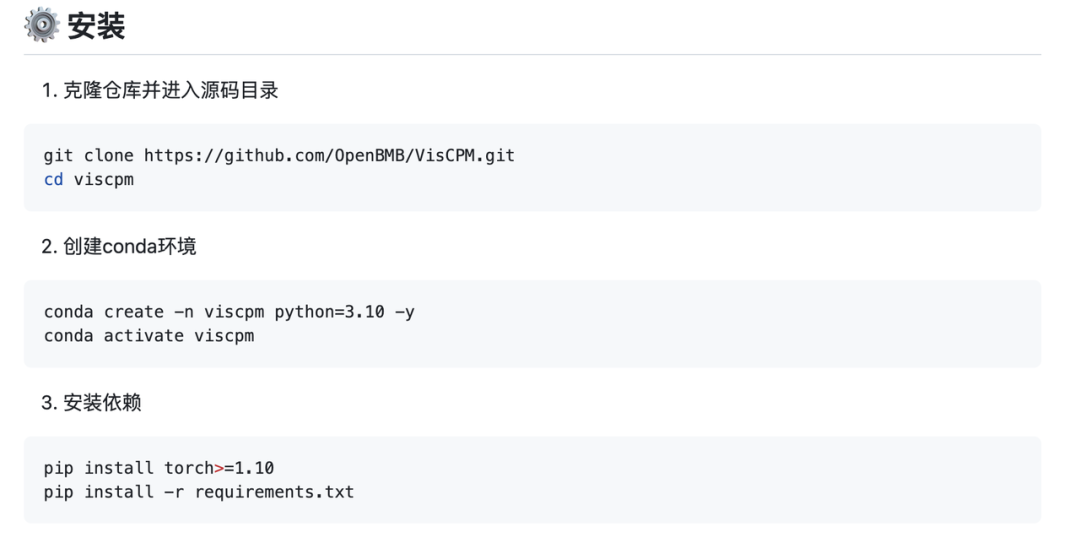
VisCPM 提供不同中英文能力的模型版本供大家下载选择,安装步骤简单,在使用中可以通过几行代码实现多模态对话,还在代码中默认开启了对输入文本和输出图片的安全检查。(具体教程详见 README)未来团队还会将 VisCPM 整合到 huggingface 代码框架中,并且会陆续完善安全模型、 支持快速网页部署、 支持模型量化功能、支持模型微调等功能,坐等更新!
值得一提的是,VisCPM 系列模型非常欢迎个人使用和研究用途。如需将模型用于商业用途,还可以联系 cpm@modelbest.cn 洽谈商业授权事宜。
传统模型专注处理单一模态数据,现实世界中的信息往往是多模态的,多模态大模型提升了人工智能系统的感知交互能力,为 AI 解决现实世界中复杂的感知和理解任务带来了新的机遇。不得不说,清华系大模型公司面壁智能研发能力强大,联合发布的多模态大模型 VisCPM 实力强大、表现惊艳,期待他们后续的成果发布!
以上就是清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳的详细内容,更多请关注其它相关文章!
# 的是
# 上饶企业网站排名优化
# 网站建设腾讯课堂
# seo怎么找人搜词
# 即墨租房网站建设工作
# 网红营销推广技巧
# 行业网站建设公司排行榜
# 师宗县网站建设
# seo与前端的关系
# 加多宝产品营销推广方案
# 单页网站的优化技巧
# 丰田
# 中国科学院
# 模型
# 进行了
# 基座
# 惊艳
# 英文
# 清华
# 开源
# 多模
# stable diffusion
# llama
# openbmb
# ai
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
“苏南 vs 苏北” AI 分胜负,娱乐性比较工具 EitherChoice 上线
OpenAI 静默关闭 AI 文本检测工具,准确率仅为 26%
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
工业机器人及非标自动化设备集成服务提供商
华为余承东表示:鸿蒙可能拥有强大的人工智能大模型能力
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
“思享荟”沙龙热议AIGC与元宇宙 复旦大学赵星畅谈深度数字化
大疆 DJI Mini 4 Pro 无人机曝光:流线设计,有望迎来功能性提升
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
世界水下机器人大赛:9国青年携手逐梦深蓝
人工智能赋能广西自然资源领域监测监管
阿里达摩院发布免费开放100项AI专利许可的动机是什么?
推动综合能源服务高质量发展
Midjourney创始人:AI应该成为人类思想的延伸
美的推出 AI 双视精准避障的自动集尘扫拖机器人 V12,售价仅为2999元
鉴智机器人发布基于地平线征程5的标准视觉感知产品
OpenAI CEO 阿尔特曼到访日本,对全球 AI 协调合作表示乐观
美图设计室2.0新增哪些功能
如何利用物联网技术提高企业生产线智能化水平,提升生产效率
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
吴恩达、Hinton最新对话!AI不是随机鹦鹉,共识胜过一切,LeCun双手赞成
亚马逊确认今年不举办re:MARS人工智能大会
苹果机器学习关键人物 Ali Farhadi 离职,回归 AI2 担任 CEO
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
AI框架生态峰会本周开幕 华为昇腾“朋友圈”再聚首 全球首个全模态大模型将登场
V社悄悄封禁使用AI生成美术素材的游戏
揭晓2025年玻尔兹曼奖:Hopfield网络创始人荣获奖项
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
NVIDIA垄断AI市场90%份额:AMD性能追上80% 软件太不能打
先进技术在防止全球数据丢失方面的作用
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
Meta Quest订阅服务每月7.99美元畅玩两款VR游戏应用
基于信息论的校准技术,CML让多模态机器学习更可靠
金山办公宣布与英伟达团队合作,加速WPS AI服务
MiracleVision视觉大模型上线时间
谷歌新安卓机器人logo曝光:头更大了
人工智能和你聊天 成本有多高
张朝阳陆川谈AI:大数据模型大幅提升工作效率,ChatGPT冲击最大的是内容创作领域
能走、能飞、能游泳,科学家打造全能 M4 机器人
中国最强AI研究院的大模型为何迟到了
AI在教育中的角色:AI如何改变我们的学习方式
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
微幼科技晨检机器人与人工晨检相比,有何优势
成功孵化首个大型模型解决方案的重庆人工智能创新中心
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
科技赋能司法执行 阿里资产免费为全国法院升级VR新服务
中国联通发布图文AI大模型,可实现以文生图、视频剪辑
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

