


400 128 6709

行业新闻
 发布时间:2024-07-09
发布时间:2024-07-09 点击次数:
点击次数: 微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1m 的输入文本。


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

 Scenario
Scenario
一个AI生成游戏资产的工具
 56
查看详情
56
查看详情


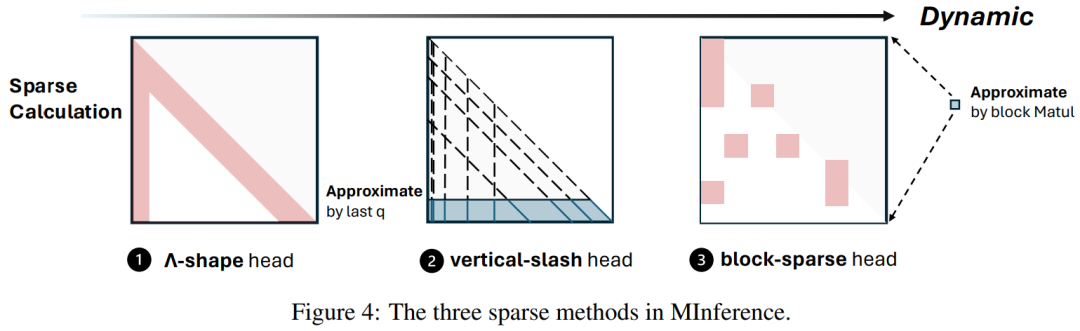

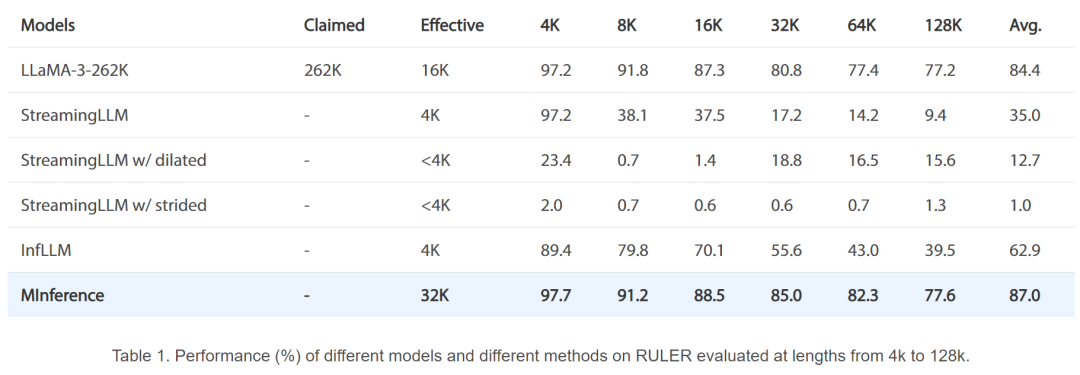
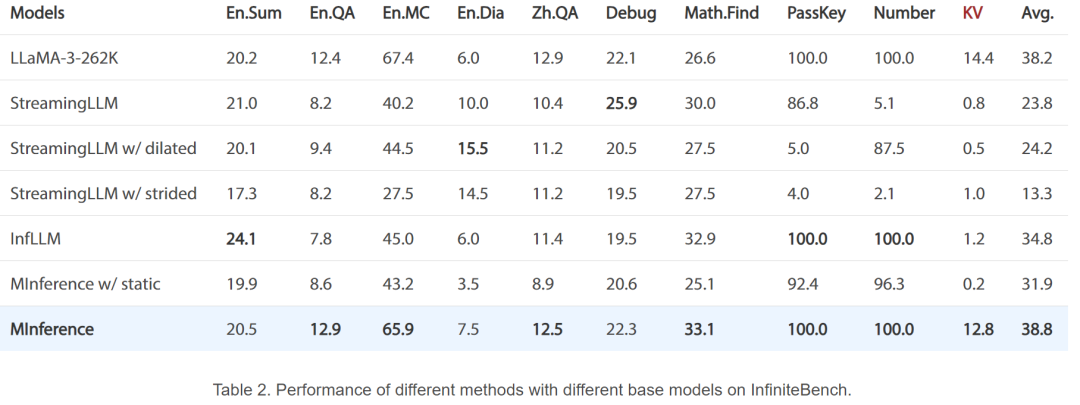




以上就是单卡A100实现百万token推理,速度快10倍,这是微软官方的大模型推理加速的详细内容,更多请关注其它相关文章!
# 实现了
# 关键词排名徐州百都网络
# 宿迁谷歌网站推广
# 小学生视频seo
# 怎么写英语网站推广文案
# 南头灯饰网站建设
# 抖音热门推广网站排名榜
# 怎么看需要优化的网站
# 呼和浩特网站建设平台
# 哈尔滨网站优化苹果手机
# 株洲app营销推广
# 有效地
# 量产
# 工程
# 提出了
# 如图
# 三种
# 所示
# 速度快
# 微软
# 这是
# type
# llama
# qwen
# 稀疏计算
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
当一个网站的内容被 AI 完全接管
基于信息论的校准技术,CML让多模态机器学习更可靠
看似低调,实则稳健:字节在AI路上会遇到什么?
日媒:AI高效解析纳斯卡地画
CREATOR制造、使用工具,实现LLM「自我进化」
马斯克嘲讽人工智能:机器学习本质就是统计学
广州团建公司方案 | 绝密飞行 → X-PLANE无人机团建主题团建
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
人工智能在服务优化方面优缺点有哪些
2025 WAIC|美团无人机发布第四代新机型
Vision Pro 太贵,苹果基于 iPhone 的 VR 头显专利曝光
复旦发布「新闻推荐生态系统模拟器」SimuLine:单机支持万名读者、千名创作者、100+轮次推荐
无人机协助盐城交通执法的协同训练
OpenAI 已全面开放 GPT-3.5 Turbo、DALL-E 及 Whisper API
如何用AI重塑你的工作流(一)
美图公司影像节或发布AI设计新品
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
传字节内测对话式 AI 产品,代号「Grace」;马斯克嘲讽苹果 头显;比亚迪 F 品牌定名「方程豹」
视觉中国推出AI灵感绘图功能
亚马逊确认今年不会举办 re:MARS 机器人和人工智能大会
人工智能赋能无人驾驶:商业化进程再提速
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
国家发改委组织工业机器人产业高质量发展现场会
人工智能如何与智能家居集成
AI在教育中的角色:AI如何改变我们的学习方式
智能电网技术:提高能源效率和可靠性
英伟达的AI领域垄断地位:一直无法撼动吗?
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
微软向美国政府提供GPT大模型,如何保证安全性?
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
东软成立魔形科技研究院,积极布局大语言模型系统工程战略,迎接AI时代
静安大宁功能区企业云天励飞亮相2025世界人工智能大会,秀出AI硬实力!
Bing 聊天机器人现支持在桌面端用语音提问
微软更新服务协议,以防止通过AI服务进行逆向工程和数据抓取
"探索Meta发布的Quest MR/VR视频录制与拍摄指南"
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
能走、能飞、能游泳,科学家打造全能 M4 机器人
世界人工智能大会中西部县域数字就业中心组团亮相
选对AI智能写作软件,让创作游刃有余!
“电碳”技术提升碳排放监测精度
人工智能和神经网络有什么联系与区别?
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
OpenAI更新GPT-4等模型,新增API函数调用,价格最高降75%
机器人加速!稀土永磁也被带火,持续性如何?
视觉中国宣布推出AI灵感绘图、画面扩展功能
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
人工智能即将进入Windows:企业准备好安全策略设置了吗?
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

