


400 128 6709

行业新闻
 发布时间:2024-06-06
发布时间:2024-06-06 点击次数:
点击次数: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
yuan+2.0-m32是一种基础架构,与yuan-2.0+2b相似,采用了一个包含32位专家的专家混合架构。其中2位专家处于活跃状态。提出并采用了一个包含32位专家的专家混合架构,以更高效地选择专家,相比采用经典路由网络的模型,其准确率提升了3.8%。yuan+2.0-m32从零开始训练,使用了2000b的token,其训练消耗仅为同等参数规模密集集合模型的9.25%。为了更好地选择专家,引入了注意力路由器,该路由器具有快速感知的能力,从而能更好地选择专家。
Yuan 2.0-M32在编码、数学及多个专业领域展现了竞争力的能力,仅使用了400亿总参数中的37亿活跃参数,以及每token7.4 GFlops的前向计算,这两项指标均仅为Llama3-70B的1/19。Yuan 2.0-M32在MATH和ARC-Challenge基准测试中超越了Llama3-70B,准确率分别达到55.89%和95.8%。Yuan 2.0-M32的模型及源代码已在GitHub:https://github.com/IEIT-Yuan/Yuan2.0-M32。
在每一个token固定计算量的情况下,采用专家混合(MoE)结构的模型可以通过增加专家数量轻松构建得比密集集模型更大规模,从而实现更高的准确性表现。实际上,在有限的计算资源下训练模型,MoE被视为减少与模型、数据集规模和有限计算能力相关的成本的卓越选择方案。
MoE(Mixture of Experts)的概念可追溯至1991年。总损失是每个专家加权损失的组合,这些专家具有独立判决的能力。稀疏门控MoE的概念最初由Shazeer等人(2017年)在翻译模型中提出。采用这种路由策略,提理时只有极少数专家被激活,而非所有专家同时被调用。这种稀疏性使得模型在计算效率损失极小的情况下,堆叠的LSTM层之间扩展了1000倍。噪声可调的Top-K门控路由由网络向softmax函数引入可调噪声并保持K值,以平衡专家利用率。近年来,随着模型规模的不断扩大,路由策略在高效分配计算资源方面受到了更多关注。
专家路由网络是MoE结构的核心。该结构通过计算token分配给每个专家的概率来选择参与计算的候选专家。目前,在大多数流行的MoE结构中,普遍采用经典路由算法,该算法执行token与每个专家特征向量之间的点积,并选择具有最大点积的专家作为获胜者。在这种选择中,专家的特征向量是独立的,忽略了专家之间的相关性。然而,MoE结构通常每次不止选择一个专家,并且不同专家之间的特征可能存在相关性。因此,在这种情况下,选择的特征向量对于每个参与计算的专家之间的点积可能存在重叠和冲突,进而影响结果的准确性。但是,MoE结构通常每次选择不止一个专家,并且不同专家之间的特征可能存在相关性,因此在这种情况下,经典路由算法选择的特征向量可能会存在重叠和冲突,影响计算准确性。为了解决这个问题,MoE结构经常采用独立的专家特征向量,这意味着每个专家被视为完全独立,而忽略了专家之间的相关性。然而,这种做法可能会导致一些问题。因此,在选择专家时,MoE结构通常不止选择一个专家,并且不同专家之间的特征可能存在相关性。在这种情况下,选择的特征向量对于每个参与计算的专家之间的点积可能存在重叠和冲突,进而影响结果的准确性。因此,MoE结构需要一种更准确的路由算法来选择最佳的专家,并且在选择时需要考
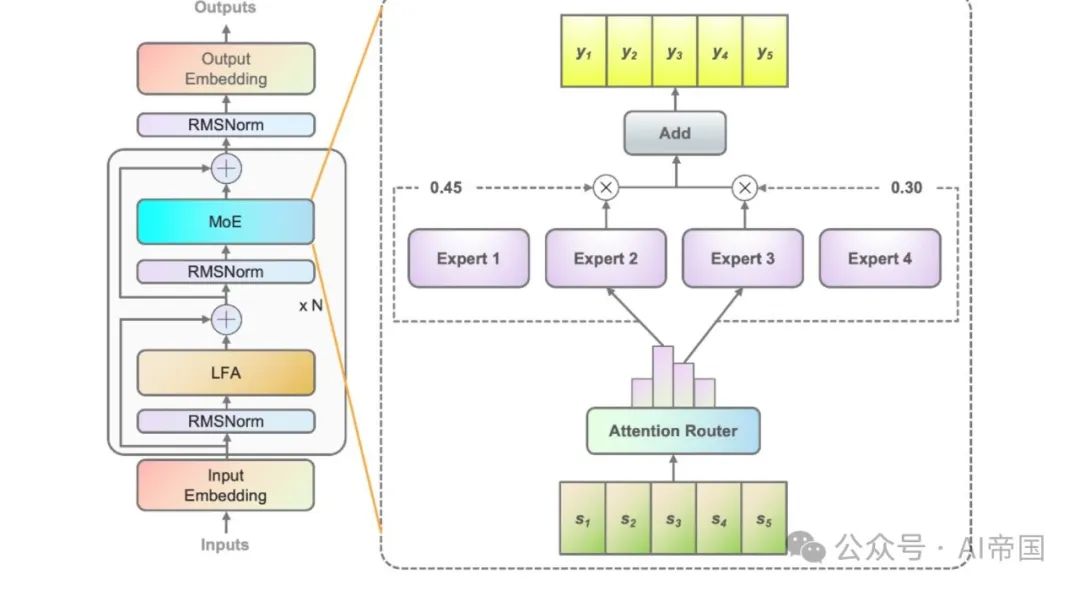
基于Yuan 2.0-2B的模型结构,Yuan 2.0引入了基于局部过滤的注意力(LFA)以考虑输入token的局部依赖性,从而提高模型的准确性。在Yuan 2.0-M32中,每一层的密集前馈网络(FFN)被替换为MoE组件。
图1展示了论文模型中应用的MoE层的架构。以四个FFN为例(实际上有32个专家),每个MoE层由一个独立的FFN作为专家组成。由于专家的路径网络将输入的token分派给相关的专家,经典的路径网络为每个专家建立了一个特征向量。并计算输入的token与每个专家特征向量之间的点积,以获得token与每个专家之间的相似度。具有最高相似度的专家将用于计算输出。最强的相似度的专家被选中激活,并参与后续计算。
 图片
图片
图1:Yuan 2.0-M32的说明。左侧图展示了Yuan 2.0架构中MoE层的扩展情况。MoE层替代了Yuan 2.0中的前馈层。右侧图展示了MoE层的结构。在论文的模型中,每个输入token将被分配给总共32个专家中的2个,而在图中论文以4个专家为例进行展示。MoE的输出是所选专家的加权和。N表示层的数量 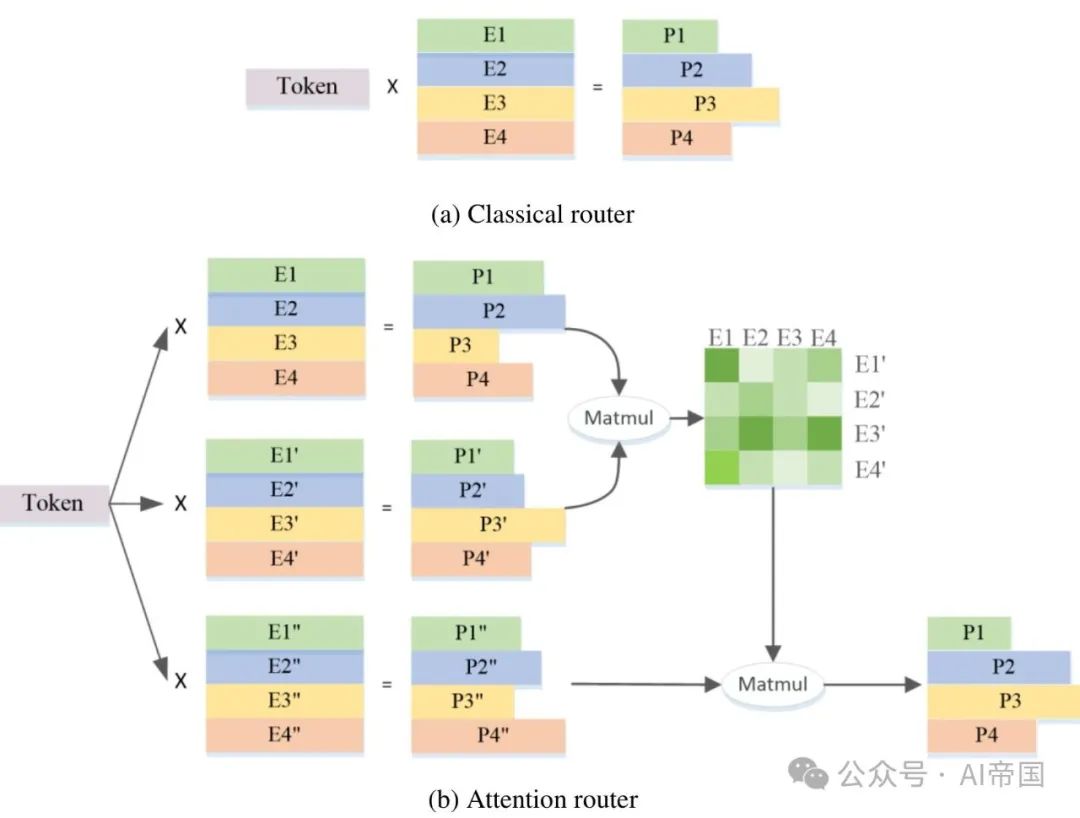 图2展示了注意力路由器结构的概览
图2展示了注意力路由器结构的概览
图2(a)展示了经典路由网络的结构。每个专家的特征向量彼此独立,计算概率时忽略了专家之间的相关性。实际上,在大多数MoE模型中,通常会选择两个或更多的专家参与后续计算,这自然带来了专家间的强相关性。考虑专家间的相关性无疑有助于提高准确性。
图2(b)展示了本工作提出的注意力路由器的架构,该新颖的路由网络通过采用注意力机制来整合专家间的相关性。构建了一个表示专家间相关性的系数矩阵,并应用于最终概率值的计算中。
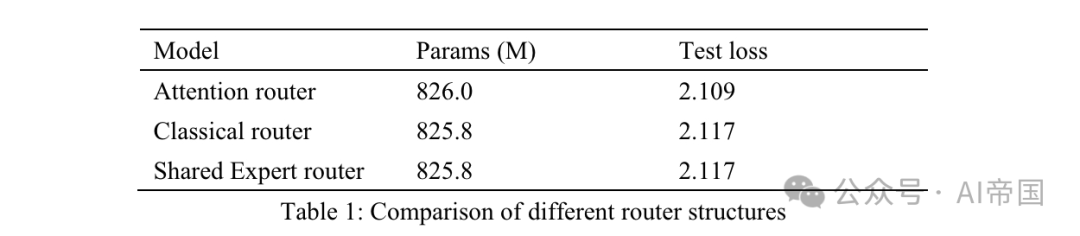 表1:不同路由结构的比较
表1:不同路由结构的比较
表1列出了不同路由器的准确性结果。论文的模型在8个可训练专家上测试了注意力路由器。经典路由器模型有8个可训练专家,以确保相似的参数规模,并且路由结构与应用于Mixtral 8*7B的结构相同,即一个线性层上的Softmax。共享专家路由器采用共享专家隔离策略与经典路由架构。有两个固定专家捕捉通用知识,以及14个可选专家中前两名作为专业专家。
MoE的输出是固定专家和路由器选出的专家的组合。所有三个模型都使用30Btoken进行训练,并使用另外10Btoken进行测试。考虑到经典路由器和共享专家路由器之间的结果,论文发现后者在训练时间增加了7.35%的情况下获得了完全相同的测试损失。共享专家的计算效率相对较低,并没有带来比经典MOE策略更好的训练准确性。因此,在论文的模型中,论文采用了不带任何共享专家的经典路由策略。与经典路由网络相比,注意力路由器的测试损失提高了3.8%。
论文通过增加专家数量并固定每个专家的参数大小来测试模型的可扩展性。训练专家数量的增加仅改变模型容量,而不改变实际激活的模型参数。所有模型均使用500亿个token进行训练,并使用另外的100亿个token进行测试。论文将激活的专家设置为2,三个模型的训练超参数相同。专家扩展效果通过训练500亿个token后的测试损失来衡量(表2)。与具有8个可训练专家的模型相比,具有16个专家的模型显示出2%的损失降低,而具有32个专家的模型显示出3.6%的损失降低。考虑到其准确性,论文为Yuan 2.0-M32选择了32个专家。
 表2:扩展实验结果
表2:扩展实验结果
Yuan 2.0-M32通过数据并行和流水线并行的组合进行训练,但不使用张量并行或优化器并行。图3展示了损失曲线,最终训练损失为1.22。
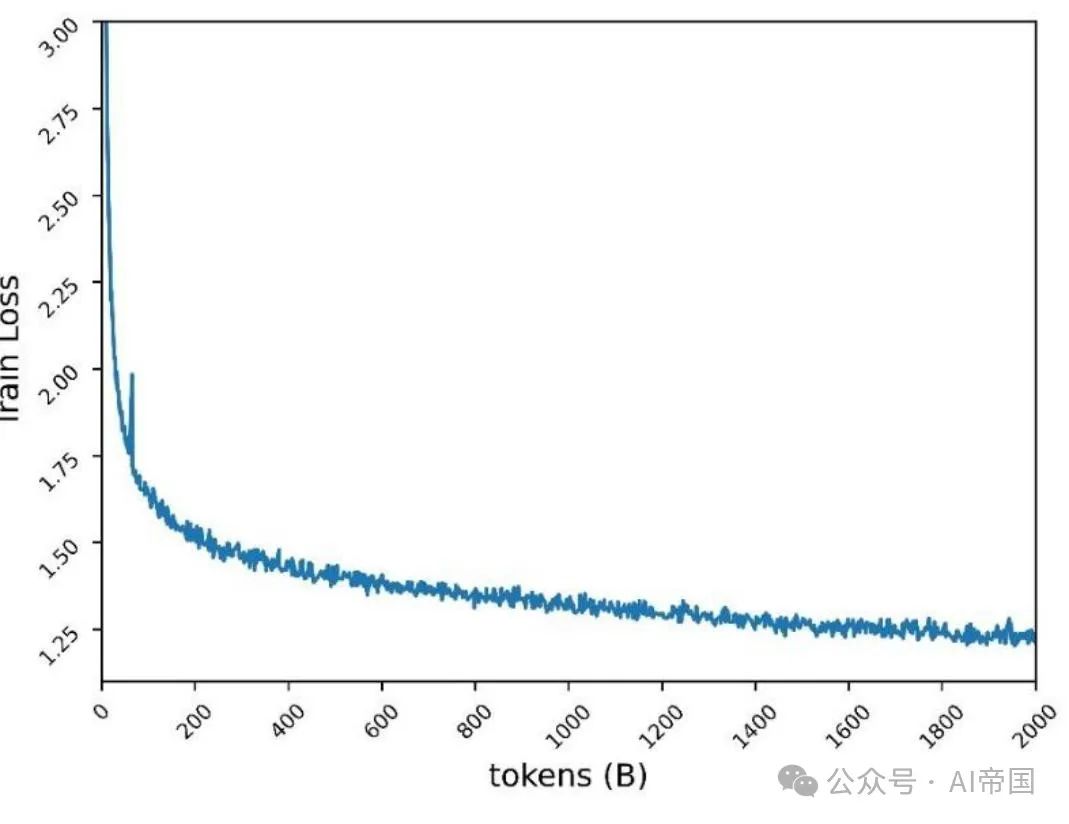 图3:Yuan2.0-M32在2000Btoken上的预训练损失
图3:Yuan2.0-M32在2000Btoken上的预训练损失
在微调过程中,论文将序列长度扩展至16384。遵循CodeLLama(Roziere et al., 2025)的工作,论文重置旋转位置嵌入(RoPE)的基频值,以避免随着序列长度增加,注意力分数的衰减。论文没有简单地将基值从1000增加到一个非常大的值(例如1000000),而是使用NTK感知(bloc97, 2025)计算新的基值。
论文还比较了预训练的Yuan 2.0-M32模型与NTK感知风格的新基值,以及与其他基值在序列长度高达16K的针检索任务中的性能。论文发现NTK感知风格的新基值40890表现更好。因此,在微调过程中应用了40890。
Yuan 2.0-M32 从零开始使用包含 2000B token 的双语数据集进行预训练。预训练的原始数据包含超过 3400B token,并根据数据质量和数量调整每个类别的权重。
综合预训练语料库由以下内容组成:
44个子数据集,涵盖了网络爬取数据、维基百科、学术论文、书籍、代码、数学和公式以及特定领域的专业知识。其中一些是开源数据集,其余由Yuan 2.0创建。
部分常见的网络爬虫数据、中文书籍、对话及中文新闻数据继承自 Yuan 1.0(吴等人,2025年)。Yuan 2.0 中的大部分预训练数据也得到了重新利用。
关于每个数据集的构建和来源的详细信息如下:
网络(25.2%):网站爬虫数据是从开源数据集和论文之前工作(Yuan 1.0)中处理过的公共爬虫数据中收集的。关于从网络上下文中提取高质量内容的Massive Data Filtering System(MDFS)的更多详情,请参考Yuan 1.0。
百科全书(1.2%)、论文(0.84%)、书籍(6.49%)和翻译(1.1%):数据继承自Yuan 1.0和Yuan 2.0数据集。
代码(47.5%):与Yuan 2.0相比,代码数据集得到了极大的扩展。论文采用了Stack v2(Lozhkov等人,2025年)中的代码。Stack v2中的注释被翻译成中文。通过与Yuan 2.0相似的方法生成了代码合成数据。
数学(6.36%):所有来自Yuan 2.0的数学数据都被重新使用。这些数据主要来自开源数据集,包括proof-pile vl(Azerbayev,2025年)和v2(Paster等人,2025年),AMPS(Hendrycks等人,2025年),MathPile(Wang,Xia和Liu,2025年)以及StackMathQA(Zhang,2025年)。使用Python创建了一个数值计算的合成数据集,以利于四则运算。
特定领域(1.93%):这是一个包含不同背景知识的数据集。
微调数据集基于Yuan 2.0中应用的数据集进行了扩展。
 灵感PPT
灵感PPT
AI灵感PPT - 免费一键PPT生成工具
 308
查看详情
308
查看详情

代码指令数据集。所有带有中文指令及部分带有英文注释的编程数据均由大型语言模型(LLMs)生成。约30%的代码指令数据为英文,其余为中文。合成数据在提示生成和数据清洗策略上模仿了带有中文注释的Python代码。
带有英文注释的Python代码收集自Magicoder-Evol-Instruct-110K和CodeFeedback-Filtered-Instruction。从数据集中提取带有语言标签(如“python”)的指令数据。
其他如C/C++/Go/J*a/SQL/Shell等语言的代码,带有英文注释,源自开源数据集,处理方式与Python代码类似。清洗策略与Yuan 2.0中的方法相似。设计了一个沙箱以提取生成的代码中可编译和可执行的行,并保留至少通过一个单元测试的行。
数学指令数据集。数学指令数据集全部继承自Yuan 2.0中的微调数据集。为提高模型通过编程方法解决数学问题的能力,论文构建了Thoughts(PoT)提示的数学数据。PoT将数学问题转换为使用Python进行计算的代码生成任务。
安全指令数据集。除了元2.0的聊天数据集外,论文还基于一个开源的安全对齐数据集构建了一个双语安全对齐数据集。论文仅从公共数据集中提取问题,并增加问题的多样性,利用大型语言模型重新生成中文和英文答案。
对于 Yuan 2.0-M32,英文和中文分词器继承自 Yuan 2.0 中应用的分词器。
论文在HumanEval上评估了Yuan 2.0-M32的代码生成能力,在GSM8K和MATH上评估了数学问题解决能力,在ARC上评估了科学知识和推理能力,并在MMLU上作为一个综合基准进行评估。
代码生成能力的评估使用HumanEval基准。评估方法和提示与元2.0中提到的相似。
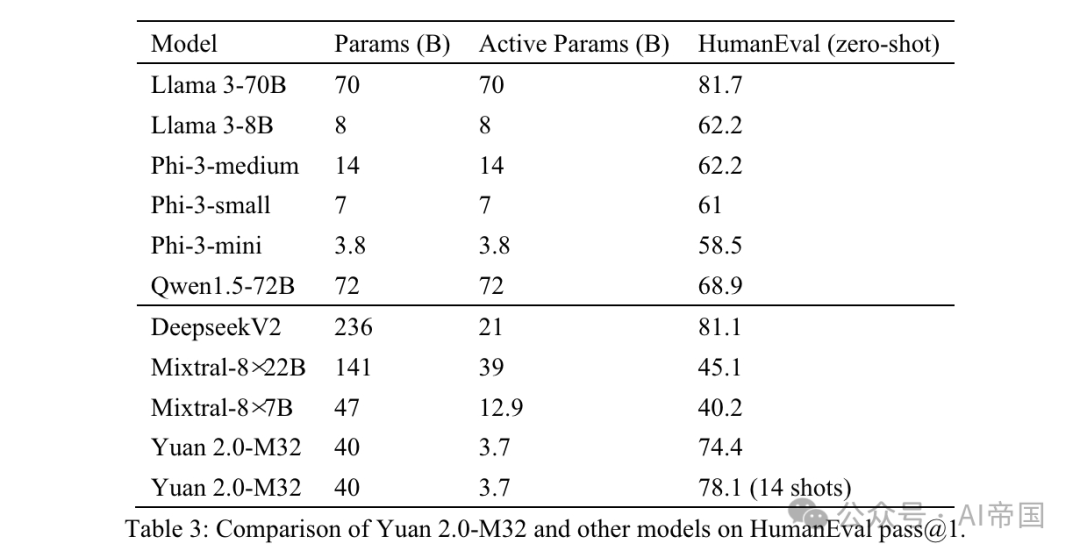 表3:Yuan 2.0-M32与其他模型在HumanEval pass @1上的比较
表3:Yuan 2.0-M32与其他模型在HumanEval pass @1上的比较
模型预期在后完成函数。生成的函数将通过单元测试进行评估。表3展示了Yuan 2.0-M32在零样本学习中的结果,并与其它模型进行了比较。Yuan 2.0-M32的结果仅次于DeepseekV2和Llama3-70B,并且远超其他模型,即使其活跃参数和计算消耗远低于其他模型。
与DeepseekV2相比,论文的模型使用的活跃参数不到其四分之一,每token的计算量不到其五分之一,同时达到了其超过90%的准确度水平。与Llama3-70B相比,模型参数和计算量的差距更大,论文仍能达到其91%的水平。Yuan 2.0-M32展示了可靠的编程能力,通过了四分之三的问题。Yuan 2.0-M32擅长小样本学习,通过14次尝试将HumanEval的准确率提高到78.0。
Yuan 2.0-M32的数学能力通过GSM8K和MATH基准进行评估。GSM8K的提示和测试策略与应用于Yuan 2 .0的相似,唯一不同的是论文使用8次尝试(表4)。
.0的相似,唯一不同的是论文使用8次尝试(表4)。
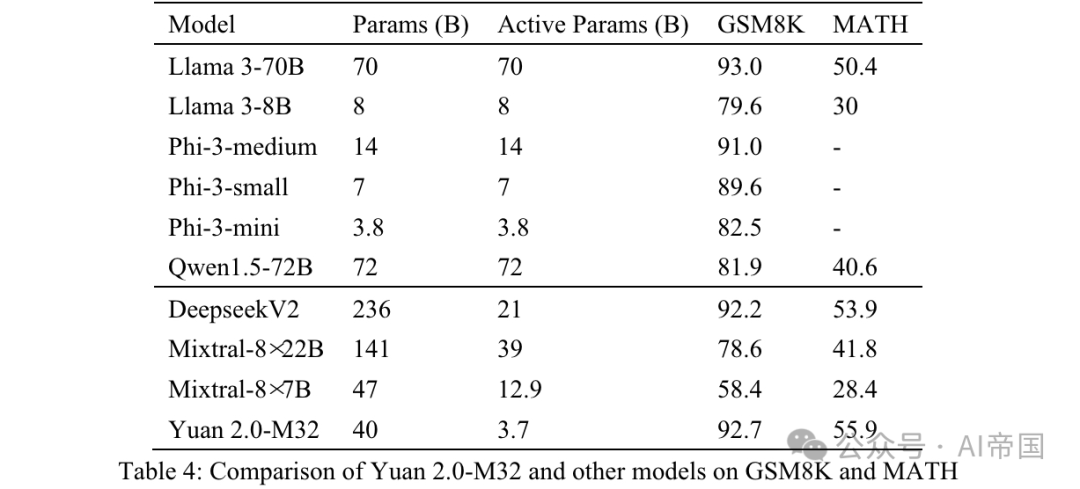 表4:Yuan 2.0-M32与其他模型在GSM8K和MATH上的比较
表4:Yuan 2.0-M32与其他模型在GSM8K和MATH上的比较
MATH是一个包含12,500个挑战性数学竞赛问答问题的数据集。该数据集中的每个问题都有一个完整的逐步解决方案,引导模型生成答案推导和解释。问题的答案可以是数值,或数学表达式(如y=2x+5,x-+2x-1,2a+b等)。Yuan 2.0-M32使用链式思维(CoT)方法,通过4次尝试生成最终答案。答案将从分析中提取并转换为统一格式。
对于数值结果,所有格式的数学等价输出均被接受。例如,分数1/2,12,0.5,0.50都转换为0.5并被视为相同结果。对于数学表达式,论文移除制表符和空格符号,并统一了节奏或音符的正则表达式。55 '5'均被接受为相同答案。处理后的最终结果与标准答案进行比较,并使用EM(精确匹配)分数进行评估。
从表4所示的结果可以看出,Yuan 2.0-M32在MATH基准上得分最高。与Mixtral-8x7B相比,后者活跃参数是Yuan 2.0-M32的3.48倍,但Yuan的得分几乎是其两倍。在GSM8K上,Yuan 2.0-M32的得分也非常接近Llama 3-70B,并优于其他模型。
大规模多任务语言理解(MMLU)涵盖了STEM、人文科学、社会科学等57个学科,从基础语言任务到高级逻辑推理任务不等。MMLU中的所有问题都是英语的多选QA问题。模型预期生成正确的选项或相应的分析。
Yuan 2.0-M32的输入数据组织如附录B所示。之前的文本被发送给模型,所有与正确答案或选项标签相关的答案被视为正确。
最终准确性通过MC1(表5)进行衡量。MMLU上的结果展示了论文模型在不同领域的能力。Yuan 2.0-M32在性能上超过了Mixtral-8x7B、Phi-3-mini和Llama 3-8B。
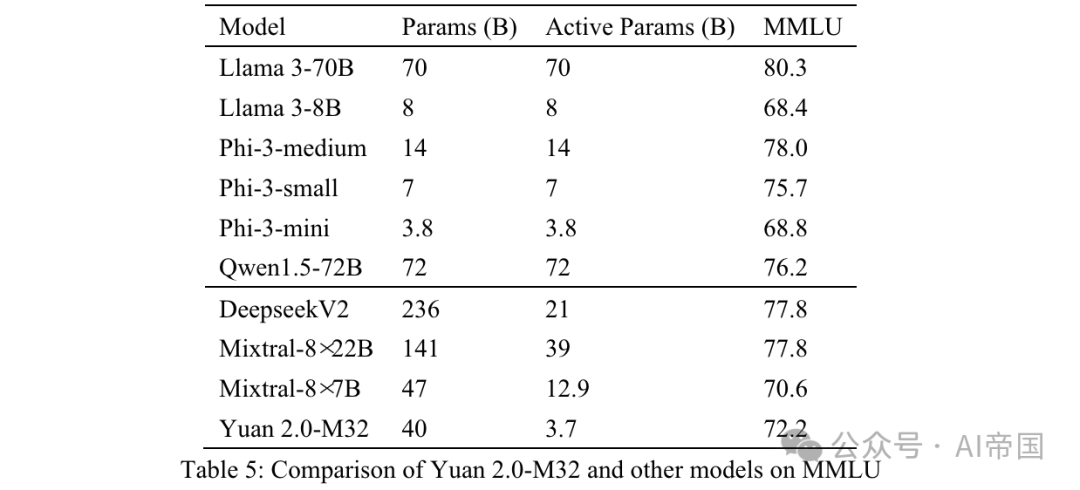 表5:Yuan 2.0-M32与其他模型在MMLU上的比较
表5:Yuan 2.0-M32与其他模型在MMLU上的比较
AI2推理挑战(ARC)基准是一个多选QA数据集,包含从3年级到9年级科学考试的问题。它分为简单和挑战两部分,后者包含需要进一步推理的更复杂部分。论文在挑战部分测试论文的模型。
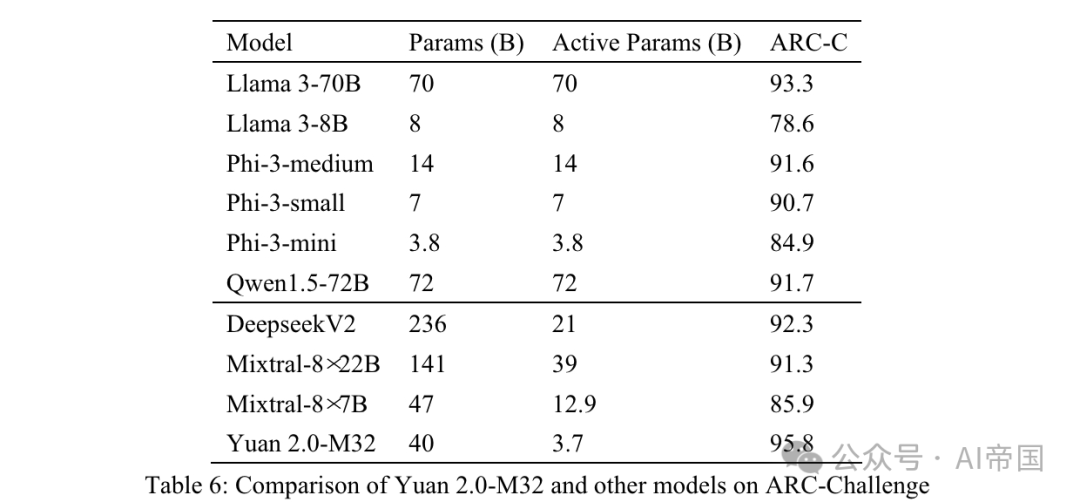 表 6:Yuan 2.0-M32 与其他模型在 ARC-Challenge 上的比较
表 6:Yuan 2.0-M32 与其他模型在 ARC-Challenge 上的比较
问题和选项直接连接并用 分隔。 之前的文本发送给模型,模型预期生成一个标签或相应的答案。生成的答案与真实答案进行比较,结果使用 MC1 目标计算。
表 6 显示的结果 ARC-C 表明,Yuan 2.0-M32 在解决复杂科学问题方面表现出色——它在这一基准上超越了 Llama3-70B。
 图片
图片
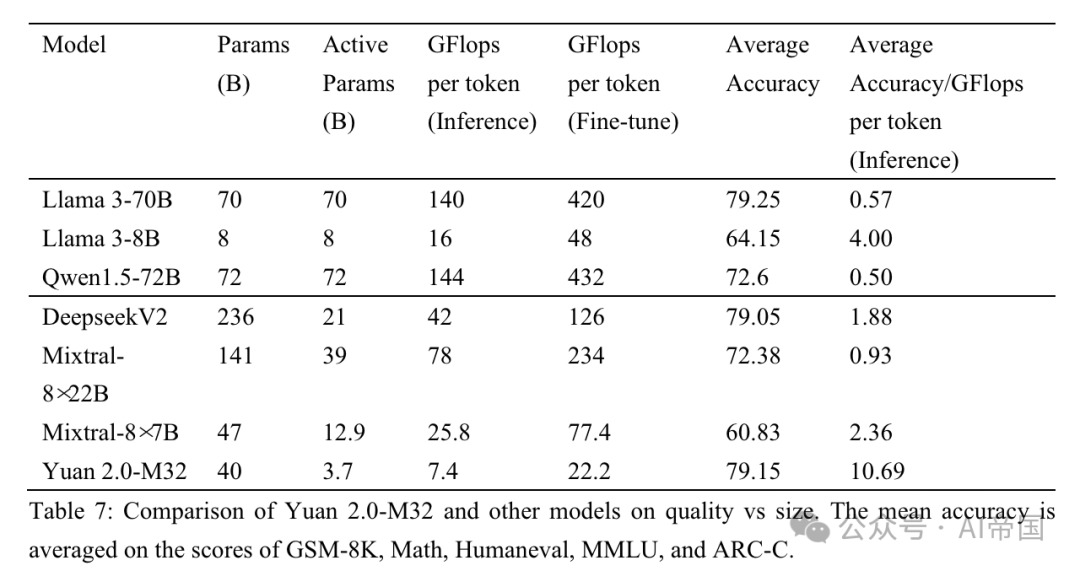
表 7:Yuan 2.0-M32 与其他模型在质量与大小上的比较。平均准确度是根据 GSM-8K、Math、Humaneval、MMLU 和 ARC-C 的分数平均得出的
论文将论文的性能与三种MoE模型(Mixtral家族、Deepseek)和六种密集模型(Qwen(Bai等,2025)、Llama家族和Phi-3家族(Abdin等,2025))进行比较,以评估Yuan 2.0-M32在不同领域的性能。表7展示了Yuan 2.0-M32与其他模型在准确度与计算量之间的比较。Yuan 2.0-M32仅使用3.7B活跃参数和每token 22.2 GFlops进行微调,这是最经济的,以获得与表中列出的其他模型相当甚至超越的结果。表7暗示了论文模型在推理过程中的卓越计算效率和性能。Yuan 2.0-M32的平均准确度为79.15,与Llama3-70B相当。而平均准确度/每token GFlops的值为10.69,是Llama3-70B的18.9倍。
论文标题:Yuan 2.0-M32: Mixture of Experts with Attention Router
论文链接:https://www.php.cn/link/a48de938587144be6be3b95682b5b948
以上就是LLM | Yuan 2.0-M32:带注意力路由的专家混合模型的详细内容,更多请关注其它相关文章!
# math
# llm
# follow
# llama
# qwen
# deepseek
# c++
# git
# python
# 混合模型
# seo必须做下去吗
# 京东网站建设机构
# 滨江区网络推广招聘网站
# 大闸蟹网络营销推广
# 营销推广比较牛的产品
# 大连市全网营销推广
# 博客网站免费建设教程
# 江门seo首页优化
# 商丘网站建设推广专家
# 南平抖音付费营销推广中心
# 在这种情况下
# 是一个
# 可调
# 门控
# 采用了
# 与其他
# 等人
# 英文
# 展示了
# 开源
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
RoboNeo安装教程
挤爆服务器,北大法律大模型ChatLaw火了:直接告诉你张三怎么判
亚马逊确认今年不举办re:MARS人工智能大会
深剖Apple Vision Pro中暗藏的“AI”
掌阅科技入选北京市通用人工智能产业创新伙伴计划第二批成员名单
Moka发布AI原生HR SaaS产品“Moka Eva”,布局AGI时代
人工智能赋能无人驾驶:商业化进程再提速
创新全场景清洁方案!海尔商用机器人首发上市
通用医疗人工智能如何革新医疗行业?
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
微幼科技晨检机器人:幼儿园健康保障的新伙伴
OpenAI CEO 山姆・阿尔特曼呼吁 AI 领域中美应当合作
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
选对AI智能写作软件,让创作游刃有余!
闪电快讯|京东推出言犀AI大模型 面向零售、医疗、物流等产业场景
两架海燕号无人机交付中国气象局 助力建设国家级机动气象观测业务
清华&中国气象局大模型登Nature:解决世界级难题,「鬼天气」预报时效首次达3小时
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
美军AI无人机“误杀”操作员,人工智能要在军事领域毁灭人类?
第四范式「式说」大模型入选《2025年通用人工智能创新应用案例集》
美图第二届影像节发布七款AI影像创作工具
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练
Spotify计划推出AI驱动的音乐播放器功能
加速电网转型升级推进新型电力系统建设
剧透!蜜小豆@2025世界人工智能大会多个亮点曝光
AIGC 风潮刮到游戏产业,巨人网络与阿里云达成“游戏 +AI ”合作
VR健身应用《FitXR》将取消Quest 1端会员服务
GPT-4是如何工作的?哈佛教授亲自讲授
IBM与NASA联手开源地理空间AI基础模型,促进气候科学领域进步
2025年贵州省青少年机器人竞赛在安举行
618京东3C数码趋势产品备受青睐 AR设备成交额同比增长15倍
飒智智能机器人核心技术与应用论坛暨一体化控制器发布会成功举办
电池比 Air 2S 大 20%,大疆 Air 3 无人机现身 FCC
发布最新版本的 PICO OS 5.7.0:支持VR头盔录屏并跨平台分享至微信
第二届光合组织AI解决方案大赛赛果揭晓
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
参议院司法听证会:AI 不易管控,有可能被恶意分子利用来研发生化武器
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
大厂出品!这个AI网站太顶了,所有功能免费用
中国AI公有云市场2025年逆势蓬勃增长,增速高达80.6%
首部国内AI辅助动画片《魔游纪:人工智能辅助篇》预告发布
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
丰田汽车研究院推出生成式人工智能汽车设计工具
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
能走、能飞、能游泳,科学家打造全能 M4 机器人
百度举办AIGC创作沙龙,现场传授AI绘画“咒语”技巧
人工智能驱动智能建筑会是未来趋势吗?
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

