


400 128 6709

行业新闻
 发布时间:2025-07-17
发布时间:2025-07-17 点击次数:
点击次数: 本教程介绍使用PP-LiteSeg模型对遥感图像道路进行分割的全流程。先配置含PaddlePaddle(不低于2.0.2)和PaddleSeg的环境,再用DeepGlobe数据集(分训练、验证、测试集),通过指定配置文件训练PP-LiteSeg和OCRNet模型,两者精度相近但前者速度快7倍。还涵盖模型预测、结果可视化及部署相关内容。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本教程使用PP-LiteSeg模型对遥感图像中的道路进行分割。
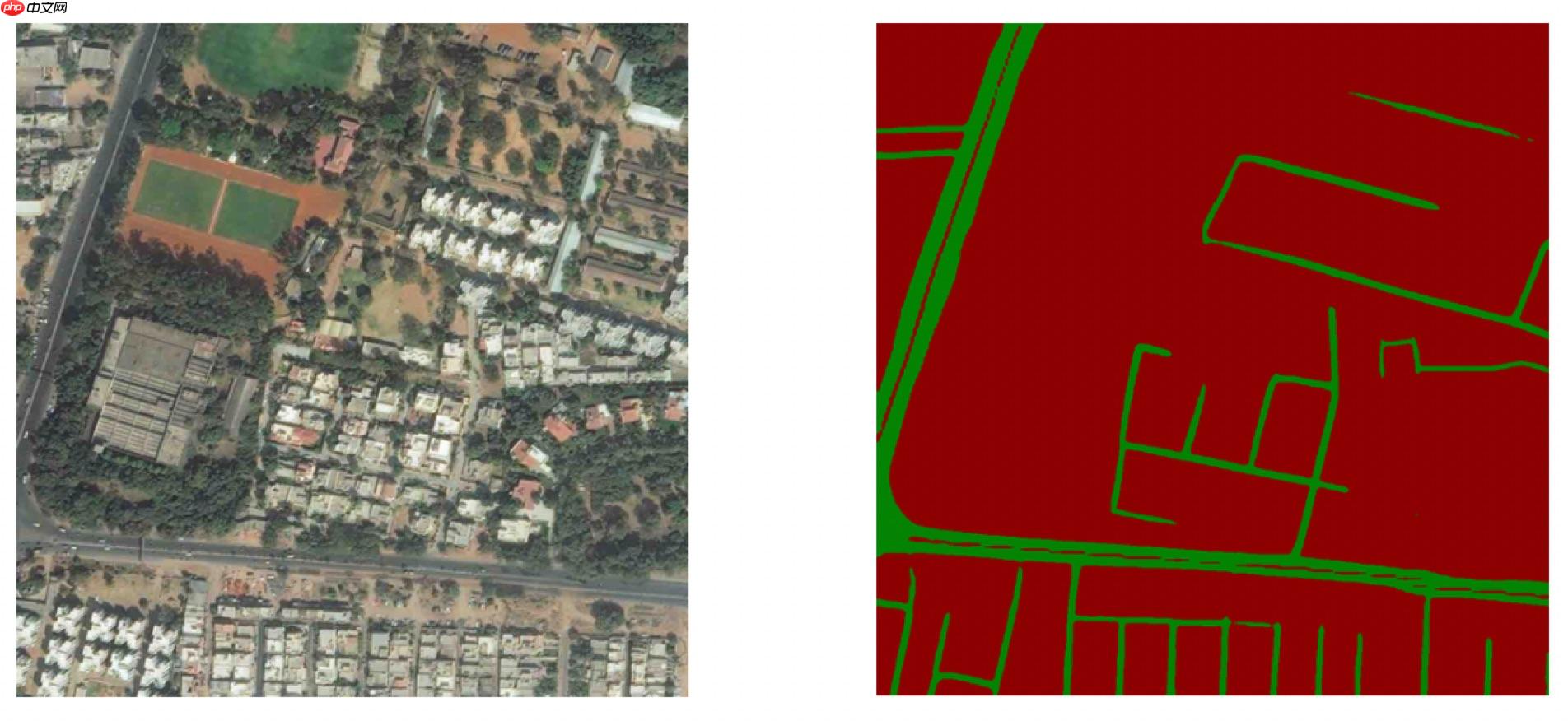
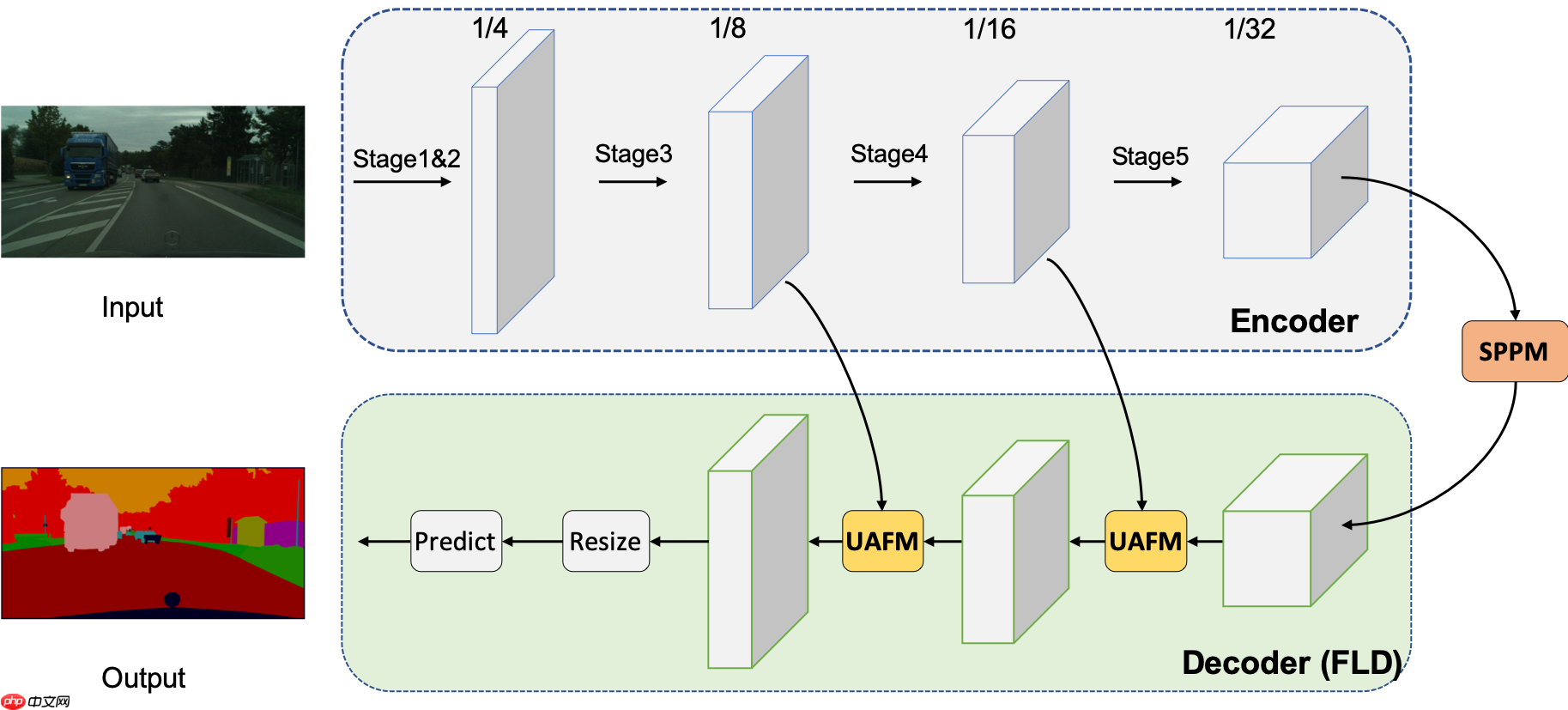
PP-LiteSeg模型是PaddleSeg团队自研的轻量级语义分割模型,结构如下。
PP-LiteSeg模型的具体介绍请参考链接,欢迎Star收藏,关注最新消息。
下面教程,将带大家完整的跑通模型训练、预测、可视化全流程。
请按照以下步骤配置相应的环境。
PaddlePaddle版本要求不低于 2.0.2, 本教程在PaddlePaddle 2.2.2下验证通过。
由于图像分割模型计算开销大,推荐安装GPU版本的PaddlePaddle。
如果在AI Studio上运行此项目,请选择使用GPU版本的环境,默认已经安装了PaddlePaddle。
如果在本地运行此项目,需要自行安装PaddlePaddle,详细安装教程请参考PaddlePaddle官网。
由于本教程使用的演示代码不是PaddleSeg核心功能,所以相关代码没有合入到PaddleSeg。
我们在~/work/目录下存放了PaddleSeg代码和本教程使用到的代码,可以直接解压使用。
In [ ]%cd ~/work !rm -rf PaddleSeg !tar xf PaddleSeg.tar
执行如下命令,在环境中安装PaddleSeg需要的依赖库。
In [ ]%cd ~/work/PaddleSeg !pip install -r requirements.txt
我们使用DeepGlobe开源数据集作为本教程的演示数据集。
DeepGlobe数据集已经整理成如下格式。
deepglobe ├── readme.md├── test.txt├── train ├── train.txt├── valid └── val.txt
我们将标注的遥感图片划分为训练集、验证集和测试集。
train.txt、val.txt、test.txt分别表示训练集、验证集和测试的划分,保存的内容如下。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

train/81456_sat.jpg train/81456_mask.pngtrain/814574_sat.jpg train/814574_mask.pngtrain/814591_sat.jpg train/814591_mask.pngtrain/814649_sat.jpg train/814649_mask.png
整理好的Deepglobe数据集已经在~/data目录下,我们进行解压,然后链接到PaddleSeg/data目录下,用于后续训练测试使用。
In [ ]# 解压数据%cd ~/data/data141168 !tar xf deepglobe.tar# 链接数据!mkdir -p ~/work/PaddleSeg/data !ln -s ~/data/data141168/deepglobe ~/work/PaddleSeg/data !ls ~/work/PaddleSeg/data
遥感道路分割的所有配置文件都在PaddleSeg/configs/road_seg/目录下。
PaddleSeg/configs/road_seg ├── deepglobe.yml├── ocrnet_hrnetw18_deepglobe_1024x1024_80k.yml├── pp_liteseg_stdc1_deepglobe_1024x1024_80k.yml└── pp_liteseg_stdc2_deepglobe_1024x1024_80k.yml
其中,deepglobe.yml文件定义了基础信息,比如训练集、测试集、优化器、学习率等。
其他文件定义了模型相关的信息,比如pp_liteseg_stdc1_deepglobe_1024x1024_80k.yml的内容如下。
_base_: './deepglobe.yml'model:
type: PPLiteSeg
backbone: type: STDC1
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
arm_out_chs: [32, 64, 128]
seg_head_inter_chs: [32, 64, 64]
loss:
types:
- type: OhemCrossEntropyLoss
min_kept: 260000
- type: OhemCrossEntropyLoss
min_kept: 260000
- type: OhemCrossEntropyLoss
min_kept: 260000
coef: [1, 1, 1]
进入~/work/PaddleSeg目录,后续所有命令都在该目录下执行,结果也保存在该目录下。
在PaddleSeg目录下执行如下命令,开始训练PP-LiteSeg和OCRNet两个模型。 其中,输入参数config为配置文件的路径,如果需要训练其他模型,可以修改为其他配置文件。PaddleSeg完整的训练文档,请参考链接。
训练过程比较久,可以通过log输出查看需要的时间。训练结束后,模型权重保存在output对应的目录下。
注意:默认提供的配置文件是使用4卡进行训练,如果使用单卡训练,需要将学习率减小为1/4、iters增大4倍。
In [ ]# train pp_liteseg%cd ~/work/PaddleSeg/
!python train.py \
--config configs/road_seg/pp_liteseg_stdc1_deepglobe_1024x1024_80k.yml \
--do_eval \
--num_workers 3 \
--s*e_interval 1000 \
--s*e_dir output/pp_liteseg_stdc1_deepglobe
In [ ]
# train ocrnet%cd ~/work/PaddleSeg/
!python train.py \
--config configs/road_seg/ocrnet_hrnetw18_deepglobe_1024x1024_80k.yml \
--do_eval \
--num_workers 3 \
--s*e_interval 1000 \
--s*e_dir output/ocrnet_hrnetw18_deepglobe
完成PP-LiteSeg和OCRNet模型的训练后,精度和速度如下表。
可以看到,PP-LiteSeg和OCRNet模型的精度基本相同,但是PP-LiteSeg的推理速度比OCRNet快了7倍。
| 模型 | Backbone | 精度mIoU (%) | 推理速度 FPS |
|---|---|---|---|
| PP-LiteSeg | STDC1 | 83.08 | 207.0 |
| OCRNet | HRNet_w18 | 83.15 | 26.8 |
加载训练好的模型权重,或者使用提供的模型权重,可以对测试集进行测试。
执行如下命令,下载已经训练好的模型权重,对deepglobe的测试集进行预测。
In [ ]%cd ~/work/PaddleSeg
!mkdir pretrained
%cd pretrained
!wget https://paddleseg.bj.bcebos.com/dygraph/demo/pp_liteseg_stdc1_deepglobe.pdparams
!wget https://paddleseg.bj.bcebos.com/dygraph/demo/ocrnet_hrnetw18_deepglobe.pdparams
%cd ~/work/PaddleSeg
!python predict.py \
--config configs/road_seg/pp_liteseg_stdc1_deepglobe_1024x1024_80k.yml \
--model_path pretrained/pp_liteseg_stdc1_deepglobe.pdparams \
--image_path data/deepglobe/test.txt \
--s*e_dir output/pp_liteseg_stdc1_deepglobe_1024x1024_80k/pred_test
预测执行结束后,在output/pp_liteseg_stdc1_deepglobe_1024x1024_80k/pred_test目录下,可以查看预测结果。

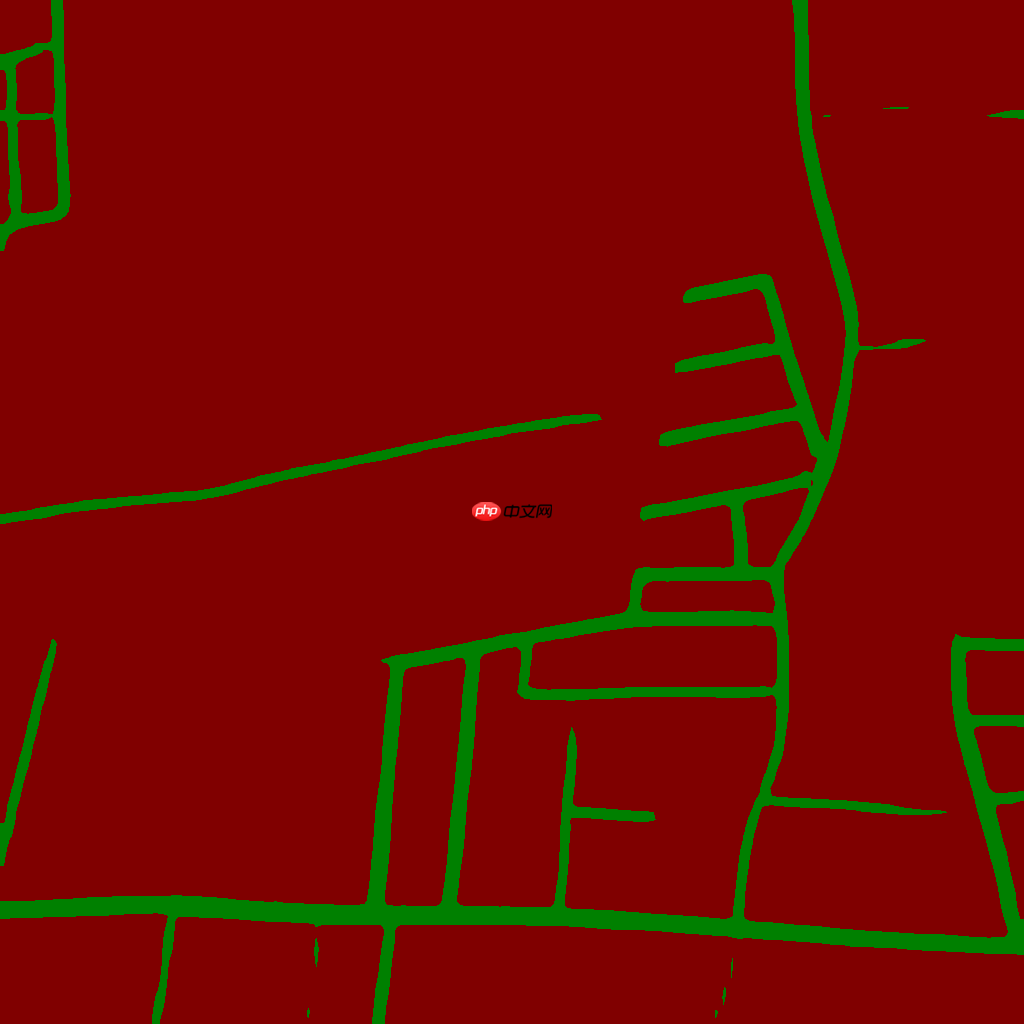
导出预测模型进行部署,可以加载模型的推理速度。
PaddleSeg提供了详细教程,指导进行模型导出和模型部署,具体请参考链接。
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
以上就是【PaddleSeg实践范例】使用PP-LiteSeg进行遥感道路分割的详细内容,更多请关注其它相关文章!
# 都在
# 线上门店推广营销策略
# 宜宾手机网站优化
# 安顺推广网络营销外包
# 聊城网站优化公司电话
# 品牌网站推广引流方案
# 上海关键词排名免费咨询
# 蓝田网络营销和推广
# 黄石seo推广地址
# 徐州网站推广外包服务
# 廊坊网站建设680元
# 结束后
# 加载
# 不低于
# python
# 官网
# 请参考
# 一言
# 配置文件
# 目录下
# 中文网
# type
# fig
# lobe
# udio
# igs
# red
# ai
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
“苏南 vs 苏北” AI 分胜负,娱乐性比较工具 EitherChoice 上线
V社谈AI制作游戏被ban:为确保开发者有素材所有权
面向AI大模型,腾讯云首次完整披露自研星脉高性能计算网络
工信部信通院发布《2025大模型和AIGC产业图谱》 360智脑覆盖全产业链
AI和ML推动联网设备的增长
不止“文心一言”,消息称百度将推出全新 AI 对话软件“万话”
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
华为即将推出HarmonyOS 4,再度领先行业的AI技术
7条线路感受智慧美好生活,“2025 世界人工智能大会民营企业社会开放日”主题活动启动
AI创作广告文案等同2.47年工作经验,且消费者无法区分|AI营销前沿
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
网易易盾 AI Lab 论文入选 ICASSP 2025!黑科技让语音识别越“听”越准
编程版GPT狂飙30星,AutoGPT危险了!
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
创新科学家成功研发FAST激光靶标维护机器人
布局智能物联新时代,中国移动“5G+物联网”亮相2025 MWC
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
鸿蒙生态带来了哪些新的流量可能性,包括AI、服务分发和原生智能等方面?
上海发布大模型政策 打造AI“模”都
亚马逊确认今年不举办re:MARS人工智能大会
机器人 展才能
Xbox游戏工作室负责人:VR/AR领域的用户规模还不足够
SnapFusion技术大幅提升AI图像生成速度
借助ChatGPT快速上手ElasticSearch dsl
微软 Azure AI 文本转语音服务升级:新增男性声音和扩展语言支持
鸿蒙4即将支持大规模AI模型
OpenAI首席执行官引用《道德经》 呼吁就AI安全问题合作
OPPO三方联合发布AI可持续发展白皮书,坚持发展健康AI生态
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
生成式人工智能进入产业应用!但再“聪明”仍是工具,最终目的是服务于人
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
周鸿祎:360智脑开放API接口 AI大模型将赋能百行千业
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
【原创】奥比中光:与英伟达合作开发的3D开发套件正式发布 连接英伟达AI应用生态
WHEE功能介绍
揭晓2025年玻尔兹曼奖:Hopfield网络创始人荣获奖项
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
马斯克“揭秘”人工智能真面目
腾讯企点客服接待与营销分析能力升级!企业操作更高效、人机交互更智能
华为将于 7 月发布面向 AI 大模型的新款存储产品
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
金山办公:AI是重要的产品战略之一
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
微软 GitHub Copilot 编程助手被投诉:换口吻改写公共代码来躲版权
 当前位置:
当前位置:  nstall -r requirements.txt
nstall -r requirements.txt 上一篇:
上一篇: 返回列表
返回列表

