


400 128 6709

行业新闻
 发布时间:2025-07-24
发布时间:2025-07-24 点击次数:
点击次数: 本文围绕水印擦除任务展开,分析其与手写文字擦除的差异及难点。介绍数据处理方式,包括生成mask、缩减数据集、随机裁剪。还阐述了模型训练及预测,A榜用Erasenet并改损失函数,B榜优化模型结构,以及模型优化和使用说明。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

赛题任务需要对添加了水印的图像,将水印擦除掉,还原原本的图的样子(图1)。
与手写文字擦除任务(图2)一个比较大的区别是:水印占据面积很大,因此对水印擦除后,还需要对被擦除的区域进行一个填补,这个是该项目的难点所在。
结论,本任务单纯使用语义分割效果不佳,需要使用带有生成能力的img2img式模型。


数据处理的方式决定了模型的设计,也会对预测的精度产生较大的影响。
(1)、为了显示的引导模型进行预测,需要结合gt和img做差值来生成mask(如下图)。(参考Erasenet论文对比结果,带有预测mask的模型的psnr要普遍高于纯的img2img的)。从GoogLeNet也可以得到启示,添加了预测mask的分支可以更有效的实现梯度传递。

(2)、由于本次比赛数据集过大,1841张本体图像,每张本体图生成551张带水印的图像,一共1841x551张,100多G。其实到后面就会发现,这个任务模型推理出mask的位置是比较简单的,因为mask是十分规律的,但是生成依然做的不够好,所以将数据集从1841x551削减到1841x20(不到10G),使得可以在aistudio上就可以加载进行训练。
(3)、参考手写文字擦除,我们同样将图片进行裁剪(随机裁剪至512, 512大小),对密集预测型任务不使用resize。

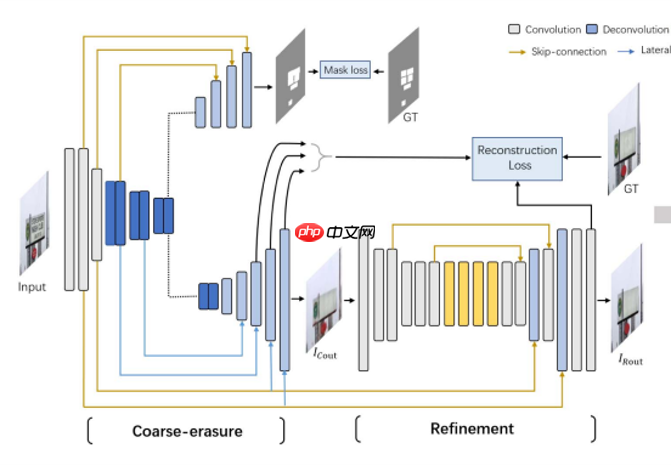
A榜用的是Erasenet,同手写文字擦除一样,我们更改了loss函数,因为这个方式比较直接效果显著(模型是需要训练的,并不是设计的越复杂越好,直接调整面向真实数据的loss设计可以有效改变模型训练的轨迹)。模型结构图如下:
预测时:先将图像重叠分块到512x512大小,对每个小块取值res = pre_image * mask + image * (1 – mask)。 也就是对模型预测为mask的地方取模型的输出,对预测为非mask的地方取输入图片的输出。这样在非mask的地方就可以保证像素差接近0(因为jpg图像本身有一些噪点,一般达不到0)。
B榜对模型进行了一次调优,方法是将网络最开始下采样和精修部分下采样的卷积替换成了SwinT模块,就像在我之前Swin那个项目里一样,将Swin和CNN成功的结合起来,做到又快又好,最终B榜分数也比较高。下图展示了原Erasenet和带swin的Erasenet改在验证集上的表现,psnr分别是31.418,33.042。

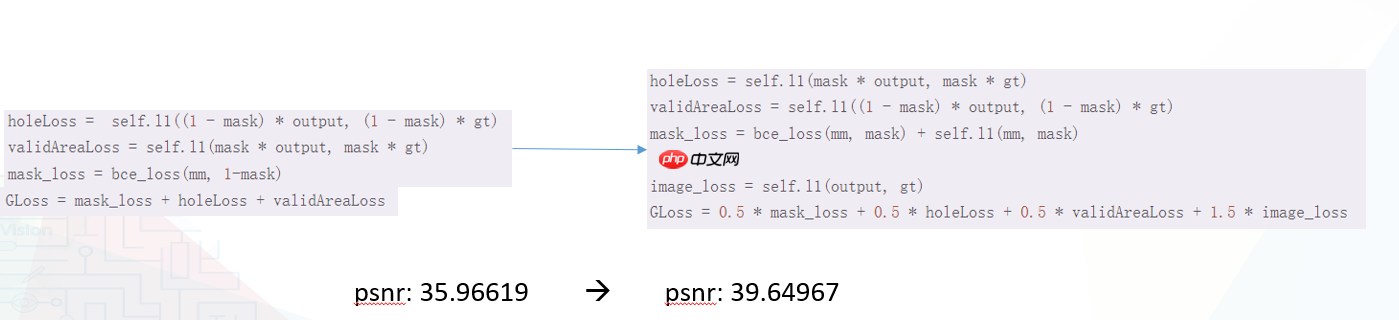
(1)、损失函数调整: 在所有超参数的调整中,我们把损失函数放在首要位置,因为其直面数据集。
调整mask损失,不仅使用bce,也使用l1。 增加image_loss,该任务对生成的要求更高,而且mask十分规整,因此加大image_loss的权重,增加到1.5,其他的则相对的调整到0.5。最后将所有loss相加,psnr有了一个很大的提升。
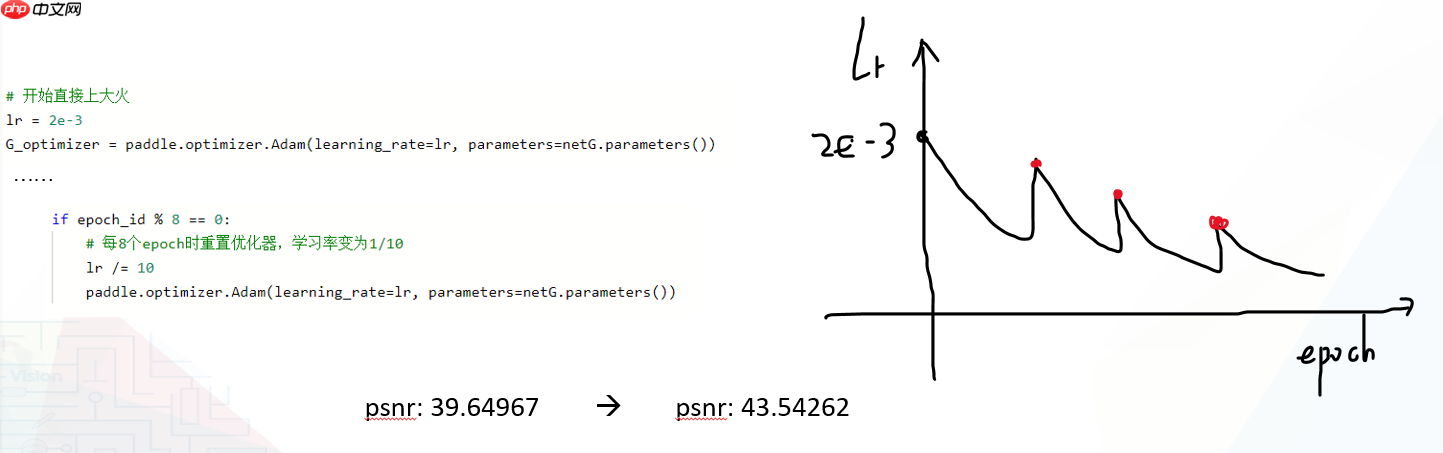
(2)、优化器调整: 在所有超参数的调整中,我们把优化器模式放在第二位置,因为其决定着训练能否达到当前模型最优。
每次重新调用优化器,就相当于对模型加载了一个经过预训练的模型。稳定后续训练,并且逃离局部平坦区域(梯度接近0)。
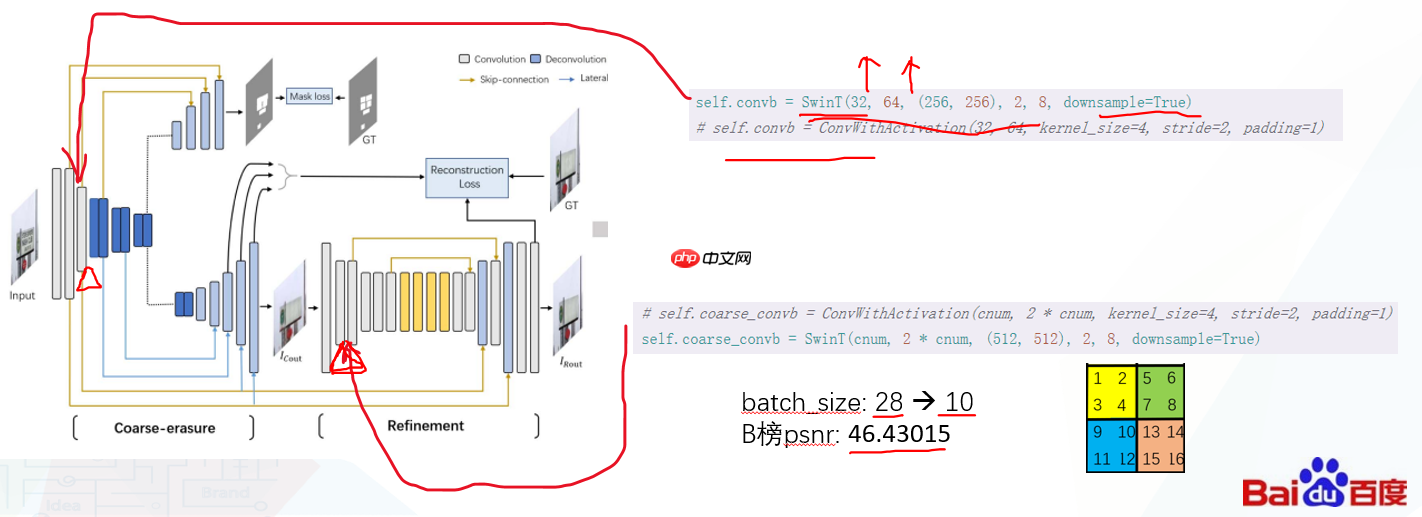
(3)、结构调整: 在所有超参数的调整中,我们把网络结构放在第三位置,因为其难调整,需要训练到平稳才能看出模型的好坏。
因为该任务,生成是比较困难的,尤其是彩色水印叠加在彩色图像上之后,虽然可以检测到mask,但是生成的效果不佳。
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
123 查看详情

由于本次比赛,水印擦除挑战赛评分提交的是模型加模型参数文件,因此就没有再加入对A,B榜的图片进行推理的notebook。因此本项目只关心于如何训练模型。
首先运行下面cell的代码,对数据集进行解压。
In [ ]# 解压文件!unzip -oq data/data145795/train_dataset.zip -d ./dataset !unzip -oq data/data145795/valid_dataset.zip -d ./dataset
数据处理的方式决定了模型的设计,也会对预测的精度产生较大的影响。与手写文字擦除任务一个比较大的区别是:水印占据面积很大,因此对水印擦除后,还需要对被擦除的区域进行一个填补,这个是该项目的难点所在。为了显示的引导模型进行预测,需要结合gt和img做差值来生成mask。如下图,从左向右依次为img,gt,mask(用自己的代码生成的,参考generate_mask.py,代码中图片路径供参考,是在本地电脑进行处理的):

另一方面,由于本次比赛数据集过大,1841张本体图像,每张本体图生成551张带水印的图像,一共1841x551张,100多G。其实到后面就会发现,这个任务模型推理出mask的位置是比较简单的,因为mask是十分规律的,但是生成依然做的不够好,所以要扩充数据集最好是找到1841张本体图像的分布然后进行扩充。
虽然机器学习定理告诉我们,训练数据量越多模型效果越好,越不容易过拟合;但这是有前提的,因为我们无法做到全批量梯度下降,真实的训练过程我们只会一次一个小batch的训练,最早期的batch对模型的梯度影响必然会被后期的batch洗掉一部分,反向传播决定了模型不能进行增量学习。所以,在显存不大的情况下,过大训练数据集起到的作用得不偿失,将数据集控制在20G之内既加快了项目打开的速度,也不会掉精度。
参考手写文字擦除,我们同样将图片进行裁剪(随机裁剪至512, 512大小),对密集预测型任务不使用resize。
总结一下:在数据处理部分,我们一共使用了三种策略, 1、缩减数据集100G-->10G 2、生成mask引导模型训练 3、随机裁剪至512x512大小
A榜用的是Erasenet,模型代码参考了https://aistudio.baidu.com/aistudio/projectdetail/3439691 , 同手写文字擦除一样,我们更改了loss函数,因为这个方式比较直接效果显著(模型是需要训练的,并不是设计的越复杂越好,直接调整面向真实数据的loss设计可以有效改变模型训练的轨迹)。模型结构图如下:
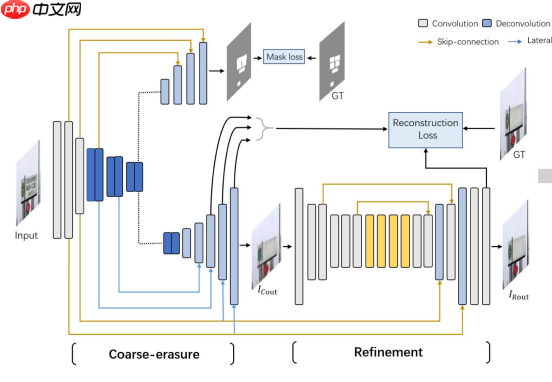
模型数据流向大体如上,loss的地方做了一定的修改。
B榜对模型进行了一次调优,方法是将网络最开始下采样和精修部分下采样的卷积替换成了SwinT模块,就像在我之前Swin那个项目里一样,将Swin和CNN成功的结合起来,做到又快又好,最终B榜分数也比较高。下图展示了原Erasenet和带swin的Erasenet改在验证集上的表现,psnr分别是31.418,33.042。

运行trainstr.ipynb可以训练原始erasenet,训练日志log和最好的模型都已包含在项目中,用visualdl即可可视化。虽然最后不会用这个模型提交,但还是放在这,可以起到一个参考的作用,因为batchsize达到28,所以训练起来是要比erasenet改快一点的。
In [ ]erasenet改是分两部分训练的,开始是用的A100,运行trainswin.ipynb即可,但是A100只能训练24小时,因此将最好的模型加载再使用V100进行训练,运行trainswinv100即可。log_swin,log_swin_v100包含了完整的训练日志。我们只是因为时间紧迫才用的A100训练的,但这并不是必要的,单纯用V100多训练几天也是可以的。
import warnings
warnings.filterwarnings("ignore")# 进行训练from visualdl import LogWriterimport osimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.io import DataLoaderfrom dataset.data_loader import TrainDataSet, ValidDataSetfrom loss.Loss import LossWithGAN_STE, LossWithSwinfrom models.swin_gan import STRnet2_changeimport utilsimport randomfrom PIL import Imageimport matplotlib.pyplot as pltimport numpy as npimport math
%matplotlib inline
log = LogWriter('log_swin_v100')def psnr(img1, img2):
mse = np.mean((img1/1.0 - img2/1.0) ** 2 ) if mse < 1.0e-10: return 100
return 10 * math.log10(255.0**2/mse) # 训练配置字典CONFIG = { 'numOfWorkers': 0, 'modelsS*ePath': 'train_models_swin_v100', 'batchSize': 10, 'traindataRoot': 'dataset/dataset', 'validdataRoot': 'dataset/valid_dataset',
'pretrained': 'train_models_swin/STE_15_43.2223.pdparams', 'num_epochs': 100, 'net': 'str', 'lr': 1e-4, 'lr_decay_iters': 40000, 'gamma': 0.5, 'seed': 9420}# 设置gpuif paddle.is_compiled_with_cuda():
paddle.set_device('gpu:0')else:
paddle.set_device('cpu')# 设置随机种子random.seed(CONFIG['seed'])
np.random.seed(CONFIG['seed'])
paddle.seed(CONFIG['seed'])# noinspection PyProtectedMemberpaddle.framework.random._manual_program_seed(CONFIG['seed'])
batchSize = CONFIG['batchSize']if not os.path.exists(CONFIG['modelsS*ePath']):
os.makedirs(CONFIG['modelsS*ePath'])
traindataRoot = CONFIG['traindataRoot']
validdataRoot = CONFIG['validdataRoot']
TrainData = TrainDataSet(training=True, file_path=traindataRoot)
TrainDataLoader = DataLoader(TrainData, batch_size=batchSize, shuffle=True,
num_workers=CONFIG['numOfWorkers'], drop_last=True)
ValidData = ValidDataSet(file_path=validdataRoot)
ValidDataLoader = DataLoader(ValidData, batch_size=1, shuffle=True, num_workers=0, drop_last=True)
netG = STRnet2_change()if CONFIG['pretrained'] is not None: print('loaded ')
weights = paddle.load(CONFIG['pretrained'])
netG.load_dict(weights)# 开始直接上大火lr = 2e-3G_optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters())
loss_function = LossWithGAN_STE()print('OK!')
num_epochs = CONFIG['num_epochs']
mse = nn.MSELoss()
best_psnr = 0iters = 0for epoch_id in range(1, num_epochs + 1):
netG.train() if epoch_id % 8 == 0: # 每8个epoch时重置优化器,学习率变为1/10
lr /= 10
paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters()) for k, (imgs, gts, masks) in enumerate(TrainDataLoader):
iters += 1
fake_images, mm = netG(imgs)
G_loss = loss_function(masks, fake_images, mm, gts)
G_loss = G_loss.sum() #后向传播,更新参数的过程
G_loss.backward() # 最小化loss,更新参数
G_optimizer.step() # 清除梯度
G_optimizer.clear_grad() # 打印训练信息
if iters % 100 == 0: print('epoch{}, iters{}, loss:{:.5f}, net:{}, lr:{}'.format(
epoch_id, iters, G_loss.item(), CONFIG['net'], G_optimizer.get_lr()
))
log.add_scalar(tag="train_loss", step=iters, value=G_loss.item()) # 对模型进行评价并保存
netG.eval()
val_psnr = 0
# noinspection PyAssignmentToLoopOrWithParameter
for index, (imgs, gt) in enumerate(ValidDataLoader):
_, _, h, w = imgs.shape
rh, rw = h, w
step = 512
pad_h = step - h if h < step else 0
pad_w = step - w if w < step else 0
m = nn.Pad2D((0, pad_w, 0, pad_h))
imgs = m(imgs)
_, _, h, w = imgs.shape
res = paddle.zeros_like(imgs)
mm_out = paddle.zeros_like(imgs)
mm_in = paddle.zeros_like(imgs)
input_array = []
i_j_list = [] for i in range(0, h, step): for j in range(0, w, step): if h - i < step:
i = h - step if w - j < step:
j = w - step
clip = imgs[:, :, i:i + step, j:j + step]
input_array.append(clip[0])
i_j_list.append((i, j)) # 并行处理进行加速
input_array = paddle.to_tensor(input_array)
input_array = input_array.cuda() with paddle.no_grad():
g_images, mm = netG(input_array)
g_images, mm = g_images.cpu(), mm.cpu() for idx in range(len(i_j_list)):
i, j = i_j_list[idx]
mm_in[:, :, i:i + step, j:j + step] = mm[idx]
g_image_clip_with_mask = imgs[:, :, i:i + step, j:j + step] * (1 - mm[idx]) + g_images[idx] * mm[idx]
res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
mm_out[:, :, i:i + step, j:j + step] = mm[idx] # for i in range(0, h, step):
# for j in range(0, w, step):
# if h - i < step:
# i = h - step
# if w - j < step:
# j = w - step
# clip = imgs[:, :, i:i + step, j:j + step]
# clip = clip.cuda()
# with paddle.no_grad():
# g_images_clip, mm = netG(clip)
# g_images_clip = g_images_clip.cpu()
# mm = mm.cpu()
# clip = clip.cpu()
# mm_in[:, :, i:i + step, j:j + step] = mm
# # mm = paddle.where(F.sigmoid(mm) > 0.5, paddle.zeros_like(mm), paddle.ones_like(mm))
# # g_image_clip_with_mask = clip * mm + g_images_clip * (1 - mm)
# g_image_clip_with_mask = clip * (1 - mm) + g_images_clip * mm
# res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
# mm_out[:, :, i:i + step, j:j + step] = mm
res = res[:, :, :rh, :rw]
mm_out = mm_out[:, :, :rh, :rw] # 改变通道
output = utils.pd_tensor2img(res)
target = utils.pd_tensor2img(gt)
mm_out = utils.pd_tensor2img(mm_out)
mm_in = utils.pd_tensor2img(mm_in)
psnr_value = psnr(output, target) print('psnr: ', psnr_value) if index in [2, 3, 5, 7, 11]:
fig = plt.figure(figsize=(20, 10),dpi=100) # 图一
ax1 = fig.add_subplot(2, 2, 1) # 1行 2列 索引为1
ax1.imshow(output) # 图二
ax2 = fig.add_subplot(2, 2, 2)
ax2.imshow(mm_in) # 图三
ax3 = fig.add_subplot(2, 2, 3)
ax3.imshow(target) # 图四
ax4 = fig.add_subplot(2, 2, 4)
ax4.imshow(mm_out)
plt.show() del res del gt del target del output
val_psnr += psnr_value
*e_psnr = val_psnr / (index + 1) print('epoch:{}, psnr:{}'.format(epoch_id, *e_psnr))
log.add_scalar(tag="valid_psnr", step=epoch_id, value=*e_psnr)
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_{}_{:.4f}.pdparams'.format(epoch_id, *e_psnr
)) if *e_psnr > best_psnr:
best_psnr = *e_psnr
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_best.pdparams')
# 训练配置字典CONFIG = { 'numOfWorkers': 0, 'modelsS*ePath': 'train_models_swin_v100', 'batchSize': 10, 'traindataRoot': 'dataset/dataset', 'validdataRoot': 'dataset/valid_dataset',
'pretrained': 'train_models_swin/STE_15_43.2223.pdparams', 'num_epochs': 100, 'net': 'str', 'lr': 1e-4, 'lr_decay_iters': 40000, 'gamma': 0.5, 'seed': 9420}# 设置gpuif paddle.is_compiled_with_cuda():
paddle.set_device('gpu:0')else:
paddle.set_device('cpu')# 设置随机种子random.seed(CONFIG['seed'])
np.random.seed(CONFIG['seed'])
paddle.seed(CONFIG['seed'])# noinspection PyProtectedMemberpaddle.framework.random._manual_program_seed(CONFIG['seed'])
batchSize = CONFIG['batchSize']if not os.path.exists(CONFIG['modelsS*ePath']):
os.makedirs(CONFIG['modelsS*ePath'])
traindataRoot = CONFIG['traindataRoot']
validdataRoot = CONFIG['validdataRoot']
TrainData = TrainDataSet(training=True, file_path=traindataRoot)
TrainDataLoader = DataLoader(TrainData, batch_size=batchSize, shuffle=True,
num_workers=CONFIG['numOfWorkers'], drop_last=True)
ValidData = ValidDataSet(file_path=validdataRoot)
ValidDataLoader = DataLoader(ValidData, batch_size=1, shuffle=True, num_workers=0, drop_last=True)
netG = STRnet2_change()if CONFIG['pretrained'] is not None: print('loaded ')
weights = paddle.load(CONFIG['pretrained'])
netG.load_dict(weights)# 开始直接上大火lr = 2e-3G_optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters())
loss_function = LossWithGAN_STE()print('OK!')
num_epochs = CONFIG['num_epochs']
mse = nn.MSELoss()
best_psnr = 0iters = 0for epoch_id in range(1, num_epochs + 1):
netG.train() if epoch_id % 8 == 0: # 每8个epoch时重置优化器,学习率变为1/10
lr /= 10
paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters()) for k, (imgs, gts, masks) in enumerate(TrainDataLoader):
iters += 1
fake_images, mm = netG(imgs)
G_loss = loss_function(masks, fake_images, mm, gts)
G_loss = G_loss.sum() #后向传播,更新参数的过程
G_loss.backward() # 最小化loss,更新参数
G_optimizer.step() # 清除梯度
G_optimizer.clear_grad() # 打印训练信息
if iters % 100 == 0: print('epoch{}, iters{}, loss:{:.5f}, net:{}, lr:{}'.format(
epoch_id, iters, G_loss.item(), CONFIG['net'], G_optimizer.get_lr()
))
log.add_scalar(tag="train_loss", step=iters, value=G_loss.item()) # 对模型进行评价并保存
netG.eval()
val_psnr = 0
# noinspection PyAssignmentToLoopOrWithParameter
for index, (imgs, gt) in enumerate(ValidDataLoader):
_, _, h, w = imgs.shape
rh, rw = h, w
step = 512
pad_h = step - h if h < step else 0
pad_w = step - w if w < step else 0
m = nn.Pad2D((0, pad_w, 0, pad_h))
imgs = m(imgs)
_, _, h, w = imgs.shape
res = paddle.zeros_like(imgs)
mm_out = paddle.zeros_like(imgs)
mm_in = paddle.zeros_like(imgs)
input_array = []
i_j_list = [] for i in range(0, h, step): for j in range(0, w, step): if h - i < step:
i = h - step if w - j < step:
j = w - step
clip = imgs[:, :, i:i + step, j:j + step]
input_array.append(clip[0])
i_j_list.append((i, j)) # 并行处理进行加速
input_array = paddle.to_tensor(input_array)
input_array = input_array.cuda() with paddle.no_grad():
g_images, mm = netG(input_array)
g_images, mm = g_images.cpu(), mm.cpu() for idx in range(len(i_j_list)):
i, j = i_j_list[idx]
mm_in[:, :, i:i + step, j:j + step] = mm[idx]
g_image_clip_with_mask = imgs[:, :, i:i + step, j:j + step] * (1 - mm[idx]) + g_images[idx] * mm[idx]
res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
mm_out[:, :, i:i + step, j:j + step] = mm[idx] # for i in range(0, h, step):
# for j in range(0, w, step):
# if h - i < step:
# i = h - step
# if w - j < step:
# j = w - step
# clip = imgs[:, :, i:i + step, j:j + step]
# clip = clip.cuda()
# with paddle.no_grad():
# g_images_clip, mm = netG(clip)
# g_images_clip = g_images_clip.cpu()
# mm = mm.cpu()
# clip = clip.cpu()
# mm_in[:, :, i:i + step, j:j + step] = mm
# # mm = paddle.where(F.sigmoid(mm) > 0.5, paddle.zeros_like(mm), paddle.ones_like(mm))
# # g_image_clip_with_mask = clip * mm + g_images_clip * (1 - mm)
# g_image_clip_with_mask = clip * (1 - mm) + g_images_clip * mm
# res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
# mm_out[:, :, i:i + step, j:j + step] = mm
res = res[:, :, :rh, :rw]
mm_out = mm_out[:, :, :rh, :rw] # 改变通道
output = utils.pd_tensor2img(res)
target = utils.pd_tensor2img(gt)
mm_out = utils.pd_tensor2img(mm_out)
mm_in = utils.pd_tensor2img(mm_in)
psnr_value = psnr(output, target) print('psnr: ', psnr_value) if index in [2, 3, 5, 7, 11]:
fig = plt.figure(figsize=(20, 10),dpi=100) # 图一
ax1 = fig.add_subplot(2, 2, 1) # 1行 2列 索引为1
ax1.imshow(output) # 图二
ax2 = fig.add_subplot(2, 2, 2)
ax2.imshow(mm_in) # 图三
ax3 = fig.add_subplot(2, 2, 3)
ax3.imshow(target) # 图四
ax4 = fig.add_subplot(2, 2, 4)
ax4.imshow(mm_out)
plt.show() del res del gt del target del output
val_psnr += psnr_value
*e_psnr = val_psnr / (index + 1) print('epoch:{}, psnr:{}'.format(epoch_id, *e_psnr))
log.add_scalar(tag="valid_psnr", step=epoch_id, value=*e_psnr)
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_{}_{:.4f}.pdparams'.format(epoch_id, *e_psnr
)) if *e_psnr > best_psnr:
best_psnr = *e_psnr
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_best.pdparams')
模型预测部分的代码保存在predict.py文件中,同在训练过程中对模型进行评估的处理方法是一致的,预测为mask的地方取模型的输出,预测为非mask的地方取输入图片的像素。这样在非mask的地方就可以保证像素差接近0(因为jpg图像本身有一些噪点,一般达不到0)。
In [ ]import osimport sysimport globimport jsonimport cv2import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom models.sa_gan import STRnet2# 加载STRnet改from models.swin_gan import STRnet2_changeimport utilsfrom paddle.vision.transforms import Compose, ToTensorfrom PIL import Image
netG = STRnet2_change()
weights = paddle.load('train_models_swin_v100/STE_12_44.8510.pdparams')
netG.load_dict(weights)
netG.eval()def ImageTransform():
return Compose([ToTensor(), ])
ImgTrans = ImageTransform()def process(src_image_dir, s*e_dir):
image_paths = glob.glob(os.path.join(src_image_dir, "*.jpg")) for image_path in image_paths: # do something
img = Image.open(image_path)
inputImage = paddle.to_tensor([ImgTrans(img)])
_, _, h, w = inputImage.shape
rh, rw = h, w
step = 512
pad_h = step - h if h < step else 0
pad_w = step - w if w < step else 0
m = nn.Pad2D((0, pad_w, 0, pad_h))
imgs = m(inputImage)
_, _, h, w = imgs.shape
res = paddle.zeros_like(imgs) for i in range(0, h, step): for j in range(0, w, step): if h - i < step:
i = h - step if w - j < step:
j = w - step
clip = imgs[:, :, i:i + step, j:j + step]
clip = clip.cuda() with paddle.no_grad():
g_images_clip, mm = netG(clip)
g_images_clip = g_images_clip.cpu()
mm = mm.cpu()
clip = clip.cpu() # mm = paddle.where(F.sigmoid(mm) > 0.5, paddle.zeros_like(mm), paddle.ones_like(mm))
# g_image_clip_with_mask = clip * mm + g_images_clip * (1 - mm)
g_image_clip_with_mask = g_images_clip * mm + clip * (1 - mm)
res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
res = res[:, :, :rh, :rw]
output = utils.pd_tensor2img(res) # 保存结果图片
s*e_path = os.path.join(s*e_dir, os.path.basename(image_path))
cv2.imwrite(s*e_path, output)
if __name__ == "__main__": assert len(sys.argv) == 3
src_image_dir = sys.argv[1]
s*e_dir = sys.argv[2] if not os.path.exists(s*e_dir):
os.makedirs(s*e_dir)
process(src_image_dir, s*e_dir)
以上就是百度网盘AI大赛——水印智能消除赛:第8名方案的详细内容,更多请关注其它相关文章!
# ai
# 网站推广的好处英语作文
# 微信怎么建设自己网站
# 河北好的网站建设指导
# 家居seo方式
# 莱芜网站建设制作推广
# 加载
# 过大
# 越好
# 为其
# 放在
# 的是
# 数据处理
# 百度网
# 电脑
# 百度网盘
# 百度
# 区别
# red
# igs
# udio
# writer
# fig
# 中文网
# 擦除
# 常州网络营销推广方案
# 园区官方网站建设
# seo购物渠道
# 吉安电子网站建设公司
# 检测网站怎样建设
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
从医疗康复外骨骼到通用人形机器人,傅利叶智能推动核心技术升级
AI 助手 Copilot 上线,微软 Win11 Dev 预览版 Build 23493 发布
一公司推出喷火机器狗,可喷出 9 米长火焰
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
「电子果蝇」惊动马斯克!背后是13万神经元全脑图谱,可在电脑上运行
人工智能和你聊天 成本有多高
MiracleVision视觉大模型上线时间
陈根:ChatGPT和人类合作开发机器人
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
ChatGPT 可以设计机器人吗?
给小朋友最好的科技礼物:乐天派桌面机器人
马斯克回应人工智能拯救世界:人类已处于“半机器人”状态
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
软通动力天枢元宇宙研究院签约落户江宁高新区
AI 冥想应用 Ogimi.ai 推出,可为用户提供教练级个性化指导
英伟达CEO宣称生成式AI已迎来“划时代时刻”
李开复:未来几年,人工智能会革了所有人的命,除非你这么做
阿里达摩院发布免费开放100项AI专利许可的动机是什么?
Gartner发布中国企业人工智能趋势浪潮3.0
微软推出人工智能模型 CoDi,可互动和生成多模态内容
AI绘画,还需要懂数学?
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
“踩油门,也要会踩刹车” 互联网企业高管谈人工智能发展
扎克伯格吐槽苹果Vision Pro:社交落后Meta太多,无法建设元宇宙
人工智能在交通领域的革新:智能解决方案彻底改变交通方式
联想创投携手12家被投企业MWC展示元宇宙、机器人等技术
微软Xbox称VR和AR还需要时间 先玩大的
AI技术加速迭代:周鸿祎视角下的大模型战略
B站内测 AI 搜索功能,输入“?”即可体验
Meta发布音频AI模型,仅需2秒片段模拟真人语音
无人机自主巡检为高海拔输电线路运维添“新彩”
实践J*a开发,构建高性能的MongoDB数据迁移工具
《自然》杂志拒绝刊登人工智能生成的图片和视频
一文读懂自动驾驶的激光雷达与视觉融合感知
旷视入选北京市通用人工智能产业创新伙伴计划
美图设计室2.0什么时候上线
马斯克发推讽刺人工智能:机器学习的本质就是统计
Meta推出VR订阅服务Quest +:每月免费玩两款游戏,7.99美元/月
推动综合能源服务高质量发展
WHEE上线时间介绍
微软面向AI初学者推出免费网络课程
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
揭晓2025年玻尔兹曼奖:Hopfield网络创始人荣获奖项
Dubbo负载均衡策略之 一致性哈希
图灵奖得主Hinton:我已经老了,如何控制比人类更聪明的AI交给你们了
国产工业机器人领域“暗潮涌动”,即将迎来新一轮复苏
IBM和NASA合作发布可追踪碳排放的开源AI基础模型
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
GPT-4是如何工作的?哈佛教授亲自讲授
 当前位置:
当前位置:  # 训练配置字典CONFIG = { 'numOfWorkers': 0, 'modelsS*ePath': 'train_models_swin_v100', 'batchSize': 10, 'traindataRoot': 'dataset/dataset', 'validdataRoot': 'dataset/valid_dataset',
'pretrained': 'train_models_swin/STE_15_43.2223.pdparams', 'num_epochs': 100, 'net': 'str', 'lr': 1e-4, 'lr_decay_iters': 40000, 'gamma': 0.5, 'seed': 9420}# 设置gpuif paddle.is_compiled_with_cuda():
paddle.set_device('gpu:0')else:
paddle.set_device('cpu')# 设置随机种子random.seed(CONFIG['seed'])
np.random.seed(CONFIG['seed'])
paddle.seed(CONFIG['seed'])# noinspection PyProtectedMemberpaddle.framework.random._manual_program_seed(CONFIG['seed'])
batchSize = CONFIG['batchSize']if not os.path.exists(CONFIG['modelsS*ePath']):
os.makedirs(CONFIG['modelsS*ePath'])
traindataRoot = CONFIG['traindataRoot']
validdataRoot = CONFIG['validdataRoot']
TrainData = TrainDataSet(training=True, file_path=traindataRoot)
TrainDataLoader = DataLoader(TrainData, batch_size=batchSize, shuffle=True,
num_workers=CONFIG['numOfWorkers'], drop_last=True)
ValidData = ValidDataSet(file_path=validdataRoot)
ValidDataLoader = DataLoader(ValidData, batch_size=1, shuffle=True, num_workers=0, drop_last=True)
netG = STRnet2_change()if CONFIG['pretrained'] is not None: print('loaded ')
weights = paddle.load(CONFIG['pretrained'])
netG.load_dict(weights)# 开始直接上大火lr = 2e-3G_optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters())
loss_function = LossWithGAN_STE()print('OK!')
num_epochs = CONFIG['num_epochs']
mse = nn.MSELoss()
best_psnr = 0iters = 0for epoch_id in range(1, num_epochs + 1):
netG.train() if epoch_id % 8 == 0: # 每8个epoch时重置优化器,学习率变为1/10
lr /= 10
paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters()) for k, (imgs, gts, masks) in enumerate(TrainDataLoader):
iters += 1
fake_images, mm = netG(imgs)
G_loss = loss_function(masks, fake_images, mm, gts)
G_loss = G_loss.sum() #后向传播,更新参数的过程
G_loss.backward() # 最小化loss,更新参数
G_optimizer.step() # 清除梯度
G_optimizer.clear_grad() # 打印训练信息
if iters % 100 == 0: print('epoch{}, iters{}, loss:{:.5f}, net:{}, lr:{}'.format(
epoch_id, iters, G_loss.item(), CONFIG['net'], G_optimizer.get_lr()
))
log.add_scalar(tag="train_loss", step=iters, value=G_loss.item()) # 对模型进行评价并保存
netG.eval()
val_psnr = 0
# noinspection PyAssignmentToLoopOrWithParameter
for index, (imgs, gt) in enumerate(ValidDataLoader):
_, _, h, w = imgs.shape
rh, rw = h, w
step = 512
pad_h = step - h if h < step else 0
pad_w = step - w if w < step else 0
m = nn.Pad2D((0, pad_w, 0, pad_h))
imgs = m(imgs)
_, _, h, w = imgs.shape
res = paddle.zeros_like(imgs)
mm_out = paddle.zeros_like(imgs)
mm_in = paddle.zeros_like(imgs)
input_array = []
i_j_list = [] for i in range(0, h, step): for j in range(0, w, step): if h - i < step:
i = h - step if w - j < step:
j = w - step
clip = imgs[:, :, i:i + step, j:j + step]
input_array.append(clip[0])
i_j_list.append((i, j)) # 并行处理进行加速
input_array = paddle.to_tensor(input_array)
input_array = input_array.cuda() with paddle.no_grad():
g_images, mm = netG(input_array)
g_images, mm = g_images.cpu(), mm.cpu() for idx in range(len(i_j_list)):
i, j = i_j_list[idx]
mm_in[:, :, i:i + step, j:j + step] = mm[idx]
g_image_clip_with_mask = imgs[:, :, i:i + step, j:j + step] * (1 - mm[idx]) + g_images[idx] * mm[idx]
res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
mm_out[:, :, i:i + step, j:j + step] = mm[idx] # for i in range(0, h, step):
# for j in range(0, w, step):
# if h - i < step:
# i = h - step
# if w - j < step:
# j = w - step
# clip = imgs[:, :, i:i + step, j:j + step]
# clip = clip.cuda()
# with paddle.no_grad():
# g_images_clip, mm = netG(clip)
# g_images_clip = g_images_clip.cpu()
# mm = mm.cpu()
# clip = clip.cpu()
# mm_in[:, :, i:i + step, j:j + step] = mm
# # mm = paddle.where(F.sigmoid(mm) > 0.5, paddle.zeros_like(mm), paddle.ones_like(mm))
# # g_image_clip_with_mask = clip * mm + g_images_clip * (1 - mm)
# g_image_clip_with_mask = clip * (1 - mm) + g_images_clip * mm
# res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
# mm_out[:, :, i:i + step, j:j + step] = mm
res = res[:, :, :rh, :rw]
mm_out = mm_out[:, :, :rh, :rw] # 改变通道
output = utils.pd_tensor2img(res)
target = utils.pd_tensor2img(gt)
mm_out = utils.pd_tensor2img(mm_out)
mm_in = utils.pd_tensor2img(mm_in)
psnr_value = psnr(output, target) print('psnr: ', psnr_value) if index in [2, 3, 5, 7, 11]:
fig = plt.figure(figsize=(20, 10),dpi=100) # 图一
ax1 = fig.add_subplot(2, 2, 1) # 1行 2列 索引为1
ax1.imshow(output) # 图二
ax2 = fig.add_subplot(2, 2, 2)
ax2.imshow(mm_in) # 图三
ax3 = fig.add_subplot(2, 2, 3)
ax3.imshow(target) # 图四
ax4 = fig.add_subplot(2, 2, 4)
ax4.imshow(mm_out)
plt.show() del res del gt del target del output
val_psnr += psnr_value
*e_psnr = val_psnr / (index + 1) print('epoch:{}, psnr:{}'.format(epoch_id, *e_psnr))
log.add_scalar(tag="valid_psnr", step=epoch_id, value=*e_psnr)
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_{}_{:.4f}.pdparams'.format(epoch_id, *e_psnr
)) if *e_psnr > best_psnr:
best_psnr = *e_psnr
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_best.pdparams')
# 训练配置字典CONFIG = { 'numOfWorkers': 0, 'modelsS*ePath': 'train_models_swin_v100', 'batchSize': 10, 'traindataRoot': 'dataset/dataset', 'validdataRoot': 'dataset/valid_dataset',
'pretrained': 'train_models_swin/STE_15_43.2223.pdparams', 'num_epochs': 100, 'net': 'str', 'lr': 1e-4, 'lr_decay_iters': 40000, 'gamma': 0.5, 'seed': 9420}# 设置gpuif paddle.is_compiled_with_cuda():
paddle.set_device('gpu:0')else:
paddle.set_device('cpu')# 设置随机种子random.seed(CONFIG['seed'])
np.random.seed(CONFIG['seed'])
paddle.seed(CONFIG['seed'])# noinspection PyProtectedMemberpaddle.framework.random._manual_program_seed(CONFIG['seed'])
batchSize = CONFIG['batchSize']if not os.path.exists(CONFIG['modelsS*ePath']):
os.makedirs(CONFIG['modelsS*ePath'])
traindataRoot = CONFIG['traindataRoot']
validdataRoot = CONFIG['validdataRoot']
TrainData = TrainDataSet(training=True, file_path=traindataRoot)
TrainDataLoader = DataLoader(TrainData, batch_size=batchSize, shuffle=True,
num_workers=CONFIG['numOfWorkers'], drop_last=True)
ValidData = ValidDataSet(file_path=validdataRoot)
ValidDataLoader = DataLoader(ValidData, batch_size=1, shuffle=True, num_workers=0, drop_last=True)
netG = STRnet2_change()if CONFIG['pretrained'] is not None: print('loaded ')
weights = paddle.load(CONFIG['pretrained'])
netG.load_dict(weights)# 开始直接上大火lr = 2e-3G_optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters())
loss_function = LossWithGAN_STE()print('OK!')
num_epochs = CONFIG['num_epochs']
mse = nn.MSELoss()
best_psnr = 0iters = 0for epoch_id in range(1, num_epochs + 1):
netG.train() if epoch_id % 8 == 0: # 每8个epoch时重置优化器,学习率变为1/10
lr /= 10
paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters()) for k, (imgs, gts, masks) in enumerate(TrainDataLoader):
iters += 1
fake_images, mm = netG(imgs)
G_loss = loss_function(masks, fake_images, mm, gts)
G_loss = G_loss.sum() #后向传播,更新参数的过程
G_loss.backward() # 最小化loss,更新参数
G_optimizer.step() # 清除梯度
G_optimizer.clear_grad() # 打印训练信息
if iters % 100 == 0: print('epoch{}, iters{}, loss:{:.5f}, net:{}, lr:{}'.format(
epoch_id, iters, G_loss.item(), CONFIG['net'], G_optimizer.get_lr()
))
log.add_scalar(tag="train_loss", step=iters, value=G_loss.item()) # 对模型进行评价并保存
netG.eval()
val_psnr = 0
# noinspection PyAssignmentToLoopOrWithParameter
for index, (imgs, gt) in enumerate(ValidDataLoader):
_, _, h, w = imgs.shape
rh, rw = h, w
step = 512
pad_h = step - h if h < step else 0
pad_w = step - w if w < step else 0
m = nn.Pad2D((0, pad_w, 0, pad_h))
imgs = m(imgs)
_, _, h, w = imgs.shape
res = paddle.zeros_like(imgs)
mm_out = paddle.zeros_like(imgs)
mm_in = paddle.zeros_like(imgs)
input_array = []
i_j_list = [] for i in range(0, h, step): for j in range(0, w, step): if h - i < step:
i = h - step if w - j < step:
j = w - step
clip = imgs[:, :, i:i + step, j:j + step]
input_array.append(clip[0])
i_j_list.append((i, j)) # 并行处理进行加速
input_array = paddle.to_tensor(input_array)
input_array = input_array.cuda() with paddle.no_grad():
g_images, mm = netG(input_array)
g_images, mm = g_images.cpu(), mm.cpu() for idx in range(len(i_j_list)):
i, j = i_j_list[idx]
mm_in[:, :, i:i + step, j:j + step] = mm[idx]
g_image_clip_with_mask = imgs[:, :, i:i + step, j:j + step] * (1 - mm[idx]) + g_images[idx] * mm[idx]
res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
mm_out[:, :, i:i + step, j:j + step] = mm[idx] # for i in range(0, h, step):
# for j in range(0, w, step):
# if h - i < step:
# i = h - step
# if w - j < step:
# j = w - step
# clip = imgs[:, :, i:i + step, j:j + step]
# clip = clip.cuda()
# with paddle.no_grad():
# g_images_clip, mm = netG(clip)
# g_images_clip = g_images_clip.cpu()
# mm = mm.cpu()
# clip = clip.cpu()
# mm_in[:, :, i:i + step, j:j + step] = mm
# # mm = paddle.where(F.sigmoid(mm) > 0.5, paddle.zeros_like(mm), paddle.ones_like(mm))
# # g_image_clip_with_mask = clip * mm + g_images_clip * (1 - mm)
# g_image_clip_with_mask = clip * (1 - mm) + g_images_clip * mm
# res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask
# mm_out[:, :, i:i + step, j:j + step] = mm
res = res[:, :, :rh, :rw]
mm_out = mm_out[:, :, :rh, :rw] # 改变通道
output = utils.pd_tensor2img(res)
target = utils.pd_tensor2img(gt)
mm_out = utils.pd_tensor2img(mm_out)
mm_in = utils.pd_tensor2img(mm_in)
psnr_value = psnr(output, target) print('psnr: ', psnr_value) if index in [2, 3, 5, 7, 11]:
fig = plt.figure(figsize=(20, 10),dpi=100) # 图一
ax1 = fig.add_subplot(2, 2, 1) # 1行 2列 索引为1
ax1.imshow(output) # 图二
ax2 = fig.add_subplot(2, 2, 2)
ax2.imshow(mm_in) # 图三
ax3 = fig.add_subplot(2, 2, 3)
ax3.imshow(target) # 图四
ax4 = fig.add_subplot(2, 2, 4)
ax4.imshow(mm_out)
plt.show() del res del gt del target del output
val_psnr += psnr_value
*e_psnr = val_psnr / (index + 1) print('epoch:{}, psnr:{}'.format(epoch_id, *e_psnr))
log.add_scalar(tag="valid_psnr", step=epoch_id, value=*e_psnr)
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_{}_{:.4f}.pdparams'.format(epoch_id, *e_psnr
)) if *e_psnr > best_psnr:
best_psnr = *e_psnr
paddle.s*e(netG.state_dict(), CONFIG['modelsS*ePath'] + '/STE_best.pdparams') 上一篇:
上一篇: 返回列表
返回列表

