


400 128 6709

行业新闻
 发布时间:2025-07-25
发布时间:2025-07-25 点击次数:
点击次数: 本文是百度论文复现赛中《Matching Networks for One Shot Learning》的复现代码说明。基于paddlepaddle-gpu2.2.2和python3.7环境,在miniImageNet数据集上完成。复现的5-way 1-shot和5-shot准确率分别为48.3%、62.2%,超论文原结果。介绍了模型背景、数据集、运行步骤、对比试验及复现心得。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本项目为百度论文复现赛《Matching Networks for One Shot Learning》论文复现代码。
依赖环境:
在miniImageNet数据集下训练和测试。
5-way Acc:
| 1-shot | 5-shot | |
|---|---|---|
| 论文 | 46.6% | 60.0% |
| 复现 | 48.3% | 62.2% |
参考论文:《Matching Networks for One Shot Learning》论文链接
在这项工作中,论文采用了基于深度神经特征的度量学习和利用外部记忆增强神经网络的最新进展。论文中框架学习了一个网络,它将一个小的带标签的support set和一个未带标签的示例映射到本身的标签上,从而避免了调整以适应new class类型的需要。然后我们定义了视觉(使用Omniglot, ImageNet)和语言任务的one-shot学习问题。与其他方法相比,论文算法在ImageNet上的one-shot精度从87.6%提高到93.2%,在Omniglot上从88.0%提高到93.8%。
模型结构如下:
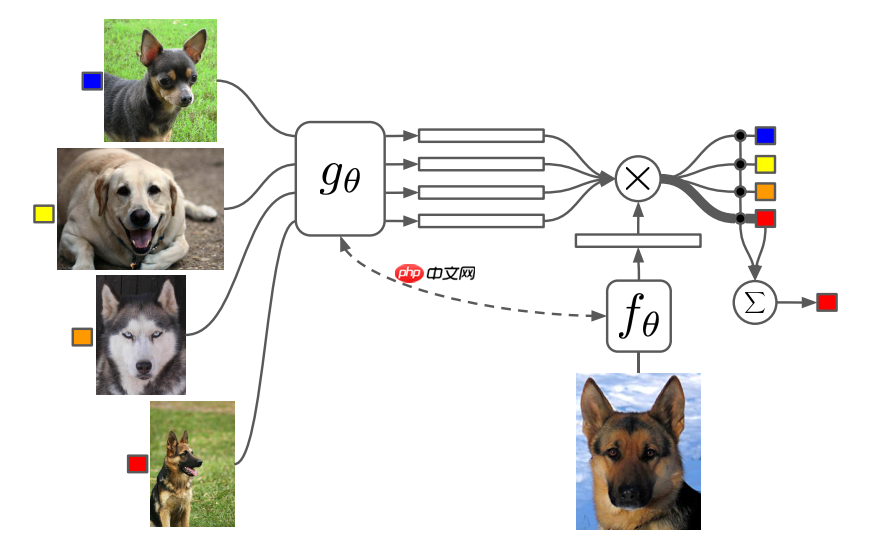
论文主要解决:基于小样本去学习归类(或别的任务),并且这个训练好的模型不需要经过调整,也可以用在对训练过程中未出现过的类别进行归类。
MatchingNet的训练对象如下公式:
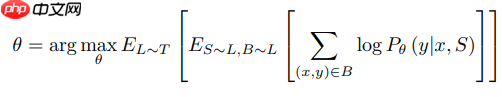
其中,一个 batch 有多个任务,一个任务有一个支持集合一个测试样本,一个支持集有多个样本对。模型应用到新的类别时不需要进行微调,是因为模型学到的是一种映射的方法,
参考论文博客
参考项目地址 复现github地址
2016年google DeepMind团队从Imagnet数据集中抽取的一小部分(大小约3GB)制作了Mini-Imagenet数据集,共有100个类别,每个类别都有600张图片,共60000张(都是.jpg结尾的文件)。
Mini-Imagenet数据集中还包含了train.csv、val.csv以及test.csv三个文件。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情


每个csv文件之间的图像以及类别都是相互独立的,即共60000张图片,100个类。
本项目5-way分类可设1-shot和5-shot。如果用5-shot可设置--n_shot 5,用1-shot可设置--n_shot 1。下面以5-shot为例。
解压miniImagenet数据集到./filelists目录下用于训练
In [1]#加载miniImagenet数据集%cd /home/aistudio/work/Paddle-MatchingNet/filelists/ !unzip -oq /home/aistudio/data/data138415/miniImagenet.zip
/home/aistudio/work/Paddle-MatchingNet/filelists
训练的模型保存在./record目录下
训练的日志保存在./logs目录下
In [ ]%cd /home/aistudio/work/Paddle-MatchingNet/ !python3 train.py --n_shot 5
将提取的特征保存在分类层之前,以提高测试速度。
加载./record目录下的模型进行特征保存
In [ ]# 可加载预先训练好的模型文件到./record目录下%cd /home/aistudio/work/Paddle-MatchingNet/record/ !unzip -oq /home/aistudio/data/data140016/checkpoint_matchingnet.zipIn [ ]
%cd /home/aistudio/work/Paddle-MatchingNet/ !python3 s*e_features.py --n_shot 5
测试之前执行!python3 s*e_features.py预先提取特征
这里展示5-shot测试结果
In [15]%cd /home/aistudio/work/Paddle-MatchingNet/ !python3 test.py --n_shot 5
/home/aistudio/work/Paddle-MatchingNet W0418 20:57:16.315918 1841 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0418 20:57:16.321213 1841 device_context.cc:465] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/framework/io.py:415: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterable) and not isinstance(obj, ( 600 Test Acc = 62.83% +- 0.73%
├─data # 数据处理包├─filelists # 数据文件├─methods # 模型方法├─logs # 训练日志├─record # 训练保存文件 │ configs.py # 配置文件│ README.md # readme│ s*e_features.py # 保存特征│ train.py # 训练│ test.py # 测试
原论文中没有对miniImageNet做数据增强,本次复现也默认未做数据增强。本项目对是否采用数据增强做了对比实验。 结果如下:
| task | 未扩增 | 扩增 |
|---|---|---|
| 1-shot | 48.3% | 45.3% |
| 5-shot | 62.2% | 60.1% |
发现做数据增强的MatchingNet出现了精度下降的情况,可参考论文复现ProtoNet的分析,项目中有设置train_aug是否做数据增强,可自行测试。
本项目参照小样本方向论文baseline给出的repo代码复现。复现过程中遇到一个比较大的问题是dataloader的设计编写,原repo设计dataloader采用了iter迭代方式,每次next的是一个sub_dataloader()。我用相同的方式使用paddle复现后,发现内存无限的增长。这个问题一直困扰,最后放弃了原repo使用sub_dataloader()的方式,采用普通的dataloader()的方法。下面给出部分实现SetDataset()的方案代码:
def __getitem__(self, i):
index = self.cl_list[i.item()]
sub_data = np.array(self.sub_meta[index])
ri = np.random.permutation(len(sub_data))
sf_sub_data = sub_data[ri][:self.batch_size]
imgs = []
targets = []
for ssd in sf_sub_data:
image_path = os.path.join(ssd)
img = Image.open(image_path).convert('RGB')
img = self.transform(img)
target = paddle.to_tensor(self.target_transform(index))
imgs.append(img)
targets.append(target)
imgs = paddle.stack(imgs, axis=0)
targets = paddle.stack(targets, axis=0)
return imgs, targets
以上就是【飞桨论文复现赛-小样本学习】MatchingNet的详细内容,更多请关注其它相关文章!
# git
# python
# 怎么做财务网站推广工作
# 河北网站优化推广有哪些
# 推广营销大的公司有哪些
# 大庆seo技巧方案
# 小红书营销推广哪家好
# 典雅近义词网站建设
# 深圳建设局网站查询
# SEO战略支援武汉
# 营销号视频多少秒合适推广
# 百度推广网站需要备案吗
# 提高到
# 加载
# 采用了
# 不需要
# 多个
# 都是
# 的是
# 目录下
# 一言
# 中文网
# fig
# udio
# igs
# csv文件
# 百度
# ai
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
上天下海登极,青岛与昇腾AI握手一起探索星辰大海
人工智能行业急缺人 AI人才年薪能达近42万元
推动企业数字化转型升级!“松江智造”摘世界人工智能大会重磅奖项
智能公司为何纷纷投身机器人领域?
全新小艺搭载AI大模型,有效提升学生和职场人士的工作效率
华为昇腾AI原生支持30多种基础大模型,包括GPT
一文看懂被英伟达看中的九号机器人移动底盘
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
Vision Pro头显重磅发布;苹果收购AR厂商Mira
AI立法迫在眉睫,如何看对行业影响?
Databricks 发布大数据分析平台 Spark 用 AI 模型 SDK:一键生成 SQL 及 FySpark 语言图表代码
“五年内人类程序员将消失”预言引争议,AI真的那么强大了吗?
微软新出热乎论文:Transformer扩展到10亿token
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
机器人 展才能
人工智能快速发展 打开就业新空间
AI成政客博弈工具,美国大选真假难辨,律师们的生意来了
全新升级的广州麦当劳:面积最大餐厅正式引入智慧机器人
AI 程序 Text With Jesus 在海外迅速受到关注:与耶稣和撒旦进行对话
全球首款AI裸眼3D平板 国产的售价破万
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
Xbox游戏工作室负责人:VR/AR领域的用户规模还不足够
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
深度学习模型综述:用于3D MRI和CT扫描的应用
国内通用人形机器人将发布、产业加速突破
人工智能赋能无人驾驶:商业化进程再提速
美图公司影像节或发布AI设计新品
用AI技术点亮老照片:Deep Nostalgia带给照片新生动感
你们的开机第一屏画面要变了!安卓机器人首次3D化
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
消息称苹果 iPhone 15 系列健康应用将深度融合 AI 技术
特斯拉机器人面世 未来将大幅提振磁材需求,引领人工智能时代
小米首次曝光 64 亿参数的 MiLM-6B AI 大模型,或将应用于小爱同学
杭州举办第19届亚运会,主题为「亚运元宇宙」的发布仪式举行
超级智能到底是什么?
重塑未来生活的五项技术趋势
云南首例达芬奇机器人微创心脏手术成功开展
羚客系统即将升级,推出全新的AI数字化工具
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
利亚德加码AI战略,与光年无限图灵机器人全面开展AI研发业务合作
海柔创新携手SAP,以机器人技术助力全球客户升级数智化竞争力
OpenAI CEO 山姆・阿尔特曼呼吁 AI 领域中美应当合作
标小智LOGO推出AI公司起名生成器“Name.GPT”
华为推出两款商用 AI 大模型存储新品,支持 1200 万 IOPS 性能
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

