


400 128 6709

行业新闻
 发布时间:2025-07-31
发布时间:2025-07-31 点击次数:
点击次数: 本文提出OrthoNets正交通道注意力网络,认为FcaNet中DCT成功源于正交核滤波器。其简化空间压缩,用多个正交核滤波器,再进行类似SE的操作。在CIFAR-10上与ResNet-18对比实验,OrthoNet-18验证精度0.9406,参数11,270,602,性能相当,表明正交核对空间压缩有效。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

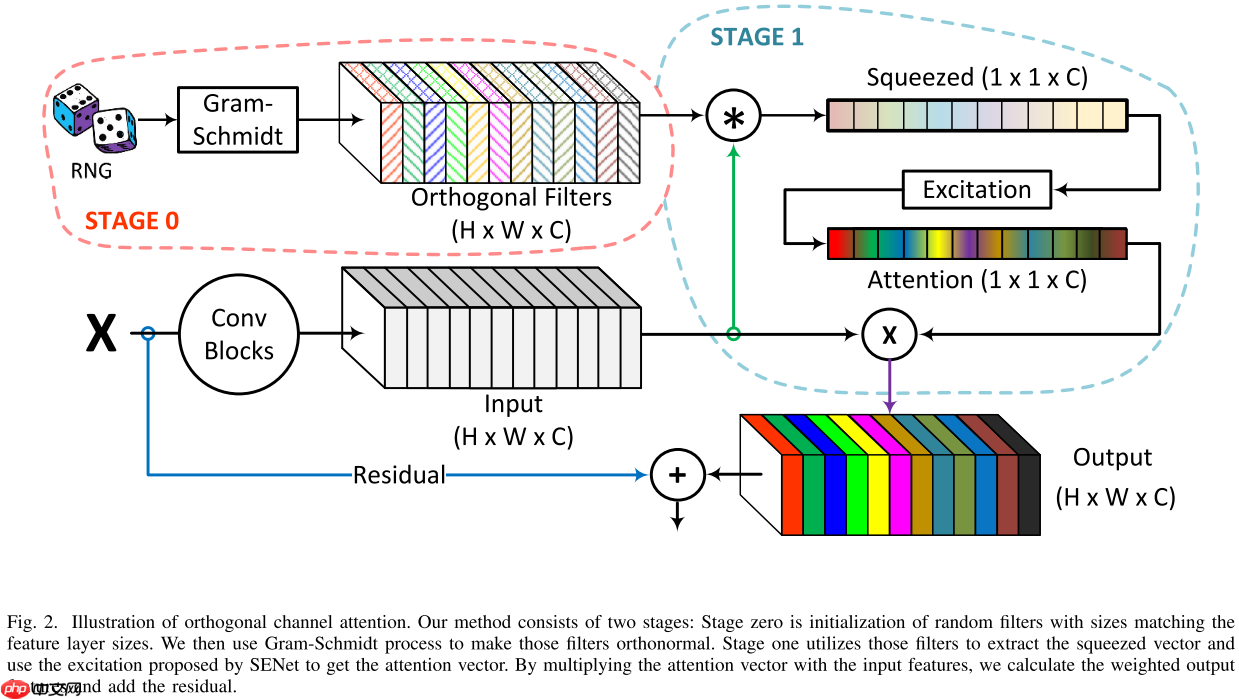
设计一种有效的通道注意机制要求人们找到一种用于最佳特征表示的有损压缩方法。尽管该领域最近取得了进展,但它仍然是一个悬而未决的问题。 FcaNet 是当前最先进的通道注意力机制,尝试使用离散余弦变换(DCT)找到这种信息丰富的压缩。 FcaNet 的一个缺点是 DCT 频率没有自然选择。为了解决这个问题,FcaNet 在 ImageNet 上进行了实验以找到最佳频率。我们假设频率的选择仅起辅助作用,而注意力过滤器有效性的主要驱动力是 DCT 内核的正交性。为了检验这个假设,我们使用随机初始化的正交滤波器构建了一个注意力机制。将此机制集成到 ResNet 中,我们创建了 OrthoNet。我们在 Birds、MS-COCO 和 Places356 上将 OrthoNet 与 FcaNet(和其他注意力机制)进行比较,并显示出优越的性能。在 ImageNet 数据集上,我们的方法可以与当前最先进的方法竞争或超越。我们的结果表明,滤波器的最佳选择是难以捉摸的,但是可以通过足够大量的正交滤波器来实现泛化。我们进一步研究了实施通道注意力的其他一般原则,例如其在网络中的位置和通道分组。
本文通过分析FcaNet中的DCT进行空间压缩的成功可能归功于正交核滤波器,因此本文简化空间压缩方法,仅使用多个正交核滤波器来进行空间压缩,然后使用于SE一样的操作:
Fortho (X)c=h=1∑Hw=1∑WKc,h,wXc,h,w
 Openflow
Openflow
一键极速绘图,赋能行业工作流
 88
查看详情
88
查看详情

%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figurefrom paddle import ParamAttrfrom paddle.nn.layer.norm import _BatchNormBaseimport mathfrom OrthoNets import *
train_tfm = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
test_tfm = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
In [4]
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000 val_dataset: 10000In [5]
batch_size=256In [6]
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
model = orthonet18(n_classes=10) paddle.summary(model, (1, 3, 32, 32))

learning_rate = 0.1n_epochs = 100paddle.seed(42) np.random.seed(42)In [ ]
work_path = 'work/model'model = orthonet18(n_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate, milestones=[30, 60, 90])
optimizer = paddle.optimizer.Momentum(parameters=model.parameters(), learning_rate=scheduler, weight_decay=5e-4)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
scheduler.step()
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================s*e====================
if val_acc > best_acc:
best_acc = val_acc
paddle.s*e(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.s*e(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
In [12]
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>In [13]
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>In [14]
import time
work_path = 'work/model'model = orthonet18(n_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:2214
model = paddle.vision.models.resnet18(num_classes=10) model.conv1 = nn.Conv2D(3, 64, 3, padding=1, bias_attr=False) model.maxpool = nn.Identity() paddle.summary(model, (1, 3, 32, 32))

learning_rate = 0.1n_epochs = 100paddle.seed(42) np.random.seed(42)In [ ]
work_path = 'work/model1'model = paddle.vision.models.resnet18(num_classes=10)
model.conv1 = nn.Conv2D(3, 64, 3, padding=1, bias_attr=False)
model.maxpool = nn.Identity()
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate, milestones=[30, 60, 90])
optimizer = paddle.optimizer.Momentum(parameters=model.parameters(), learning_rate=scheduler, weight_decay=5e-4)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record1 = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record1 = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record1['train']['loss'].append(loss.numpy())
loss_record1['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
scheduler.step()
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record1['train']['acc'].append(train_acc)
acc_record1['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record1['val']['loss'].append(total_val_loss.numpy())
loss_record1['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record1['val']['acc'].append(val_acc)
acc_record1['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================s*e====================
if val_acc > best_acc:
best_acc = val_acc
paddle.s*e(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.s*e(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
plot_learning_curve(loss_record1, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>In [19]
plot_learning_curve(acc_record1, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>In [20]
##### import timework_path = 'work/model1'model = paddle.vision.models.resnet18(num_classes=10)
model.conv1 = nn.Conv2D(3, 64, 3, padding=1, bias_attr=False)
model.maxpool = nn.Identity()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:2232
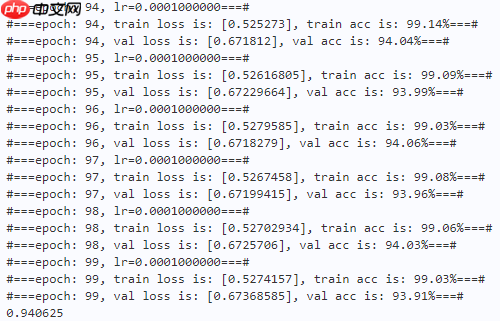
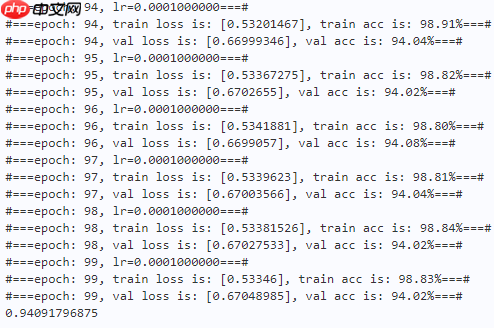
| Model | Val Acc | Parameter |
|---|---|---|
| OrthoNet-18 | 0.9406 | 11,270,602 |
| ResNet-18 | 0.9409 | 11,183,562 |
本文发现正交核对空间压缩和获得良好的全局表示非常有用,因此本文使用正交核来替换GAP操作,取得了不错的性能。(可能CIFAR-10太简单了,性能没啥提高,后续可以换CIFAR-100等数据集试试)
以上就是【BigData 2025】OrthoNets:正交通道注意力网络的详细内容,更多请关注其它相关文章!
# git
# 自然选择
# 取得了
# 是一个
# 官网
# 最先进
# 多个
# 一言
# coco
# fig
# igs
# red
# ai
# python
# 中文网
# 361如何推广网站
# 德庆网站建设优化
# 官方网站建设搭建
# 网络接单就找乐云seo
# 深圳网站群发优化
# 金华网站建设论坛
# 永康网站建设网络推广
# 罗田seo搜索推广平台
# wordpress网站排名优化
# 数字营销自助推广怎么用
# 工作流
# 悬而未决
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
NVIDIA垄断AI市场90%份额:AMD性能追上80% 软件太不能打
美图秀秀“AI 扩图”功能上线,可根据图像生成更大画幅
IBM和NASA合作发布可追踪碳排放的开源AI基础模型
CharacterAI - 也许会成为会话人工智能的未来
1.6亿美元收购Singularity AI,昆仑万维布局通用人工智能
AI绘画,还需要懂数学?
尼康尼克尔 Z 180-600mm f/5.6-6.3 VR 镜头发布,12499 元
五项人工智能尚未能够实现的任务
用AI技术点亮老照片:Deep Nostalgia带给照片新生动感
苹果2万5的AR遭遇砍单95%:不及预期
AI智能室内效果图设计软件效果,确实惊到我了!
AI 作画工具 Midjourney 推出“pan”功能,可平移扩展图片外场景
生成式人工智能如何改变云安全的游戏规则
杀入生成式AI的亚马逊云科技,能否再次生成未来?
AI和ML推动联网设备的增长
人工智能进入绿植界,智能庭院市场初具规模
即时 AI再次升级 30秒生成自带动效的网页 生成速度提升100%
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
人工智能如何帮助制造业?
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
热点 | 人工智能黄金时代开启
2025“春晖杯”人工智能专场对接活动举办
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
B站内测 AI 搜索功能,输入“?”即可体验
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
微软 Azure AI 文本转语音服务升级:新增男性声音和扩展语言支持
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
加强高质量数据供应能力,促进通用人工智能大模型领域的创新
官宣!爱康AI未来之夜三大亮点提前剧透!
九号公司主导制定短途交通和送物机器人领域首个国际标准,标志着零的突破发布
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
普林斯顿大学推出 Infinigen AI 模型,生成真实自然环境 3D 场景
RoboNeo安装教程
联想浏览器引入小乐 AI 助手,成功接入百度文心一言大模型,经过实测证实
AI创作广告文案等同2.47年工作经验,且消费者无法区分|AI营销前沿
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
华为盘古AI模型实现秒级全球气象预报时间缩短
天翼云在国际AI顶会大模型挑战赛中获得冠军
类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练
Meta发布音频AI模型,仅需2秒片段模拟真人语音
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
视觉中国宣布推出AI灵感绘图、画面扩展功能
当人工智能开始写高考作文?作家陈崇正、朱山坡谈文学与未来
J*a与人工智能结合:构建智能云服务
加强能源消费绿色转型政策引导
MiracleVision视觉大模型
 当前位置:
当前位置:  Net-18对比实验,OrthoNet-18验证精度0.9406,参数11,270,602,性能相当,表明正交核对空间压缩有效。
Net-18对比实验,OrthoNet-18验证精度0.9406,参数11,270,602,性能相当,表明正交核对空间压缩有效。 上一篇:
上一篇: 返回列表
返回列表

