


400 128 6709

行业新闻
 发布时间:2024-07-19
发布时间:2024-07-19 点击次数:
点击次数: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

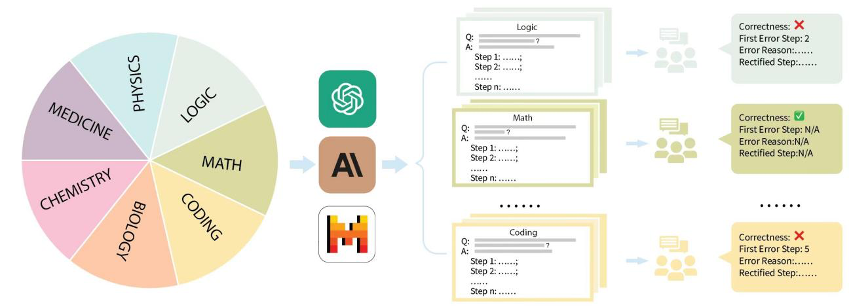
表现最佳大模型是它?
接下来,让我们结合MR-Ben工作中给出的具体例子,看看为什么说逐步作答生成最终答案的方式和相关评测不靠谱。
作为被评测的“阅卷”模型,GPT4-Turbo并未发现第二步所隐藏的计算错误:
模型解答步骤:
步骤5:选项D(37)满足所有条件,是正确答案。
模型解答正确性:不正确
首次错误步骤:步骤2
模型解答错误原因:
在步骤2中,模型错误计算了43除以4的余数为1而不是3。模型假设当43除以4时余数是1,但余数应该是3。这里有一个计算错误。
当43除以4,余数是1。当43除以3,余数是1。当43除以5,余数是3,不是2。因此,43不是正确答案。
 码上飞
码上飞
码上飞(CodeFlying) 是一款AI自动化开发平台,通过自然语言描述即可自动生成完整应用程序。
 430
查看详情
430
查看详情

模型回复:
-步骤1:步骤检查67除以4和3的余数,发现它符合被4除余3的条件,这是一个正确的验证。
-步骤2:检查43除以4、3、5的余数,发现1、3、5的余数正确匹配预期,除了5的余数不符合条件。
-步骤3:步骤计算57除以4和3的余数,余数分别是1和0。当57除以3时余数不符合条件。
-步骤4:步骤检查并验证37除以4、3、5的余数,发现所有预期的余数都准确,得出37满足题目中的所有条件。
可以看到,当给定问题、确定的解答过程,评测语言模型的方式就转换成了让模型对解答过程进行“阅卷”并评判正误、指出错误位置及原因。其中解答过程的正误,潜在的出错位置可以通过与标注结果进行比对来计算。而模型出错步骤和原因的评测,则可以交由GPT4,通过比较标注人员给出的错误原因解释和模型的错误原因解释,来判断模型是否正确。
从评测方式来看,MR-Ben所提出的方法需要模型对于解题过程的每一个步骤的前提、假设、逻辑都进行细致分析,并对推理过程进行预演来判断当前步骤是否能导向正确答案。fenye1. 这种“阅卷”式的评测方式从难度上远超于仅答题的评测方式,但可有效避免模型背题所导致的分数虚高问题。而只会背题的 学生很难成为一名合格的阅卷老师。
学生很难成为一名合格的阅卷老师。
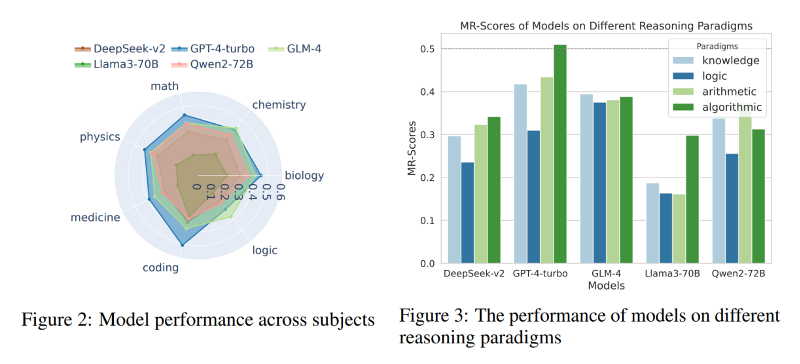
Qwen和Deepseek发布的开源模型哪怕在全球梯队里,PK闭源模型效果也不逊色。
不同的闭源模型定价策略和实际表现耐人寻味。在使用场景里关注推理能力的小伙伴,可以对照价格和能力找到自己心仪的模型去使用。
低资源场景下,小模型也有不少亮点,MR-Ben评测中Phi-3-mini在一众小模型里脱颖而出,甚至高于或持平几百亿参数的大模型,展现出了微调数据的重要性。
MR-Ben场景包含复杂的逻辑解析和逐步推断,Few-shot模式下过长的上下文反而会使得模型困惑,造成水平下降的后果。
MR-Ben评测了不少生成-反思-重生成的消融实验,查看不同提示策略的差异,发现对低水平的模型没有效果,对高水平的模型如GPT4-Turbo效果也不明显。反而对中间水平的模型因为总把错的改对,对的改错,效果反而略有提升。
将MR-Ben评测的科目粗略划分成知识型、逻辑型、计算型、算法型后,不同的模型在不同的推理类型上各有优劣。
贾佳亚团队已在github上传一键评测的方式,欢迎所有关注复杂推理的小伙伴在自家的模型上评测并提交,团队会及时更新相应的leaderboard。
对了,使用官方的脚本一键评测,只需花费12M tokens左右,过程非常丝滑,不妨一试!
参考
Training Verifiers to Solve Math Word Problems(https://arxiv.org/abs/2110.14168)
Measuring Massive Multitask Language Understanding(https://arxiv.org/abs/2009.03300)
LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning(https://arxiv.org/abs/2007.08124)
MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation(https://arxiv.org/abs/2405.11430)
Sparks of Artificial General Intelligence: Early experiments with GPT-4(https://arxiv.org/abs/2303.12712)
Qwen Technical Report(https://arxiv.org/abs/2309.16609)
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(https://arxiv.org/abs/2405.04434)
Textbooks Are All You Need(https://arxiv.org/abs/2306.11644)
Large Language Models Cannot Self-Correct Reasoning Yet(https://arxiv.org/abs/2310.01798)
以上就是贾佳亚团队联手剑桥清华等共推评测新范式 一秒侦破大模型“高分低能”的详细内容,更多请关注其它相关文章!
# git
# 工程
# 也不
# 可以看到
# 作答
# 开源
# 清华
# 高分低能
# 剑桥
# qwen
# claude
# gemini
# deepseek
# 双桥大型网站推广
# 银川网站建设哪个好点
# 国内seo软件教程
# 营销推广平台首选产品是
# 个人网站建设源码
# 河南营销推广传媒
# 山西seo助手有哪些公司
# 建湖网站推广怎么样赚钱
# 网站搜索引擎优化 原因
# 上海网站建设与规划案例
# 第一个
# 进行了
# 成了
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
世界上第一个完全由人工智能驱动的图像编辑器!
探展WAIC | 第四范式“式说”聚焦toB大模型,布局生成式AI重构企业软件
讯飞星火大模型实现升级 助力通用人工智能人才培养
Valve 将拒绝采用 AI 生成未知版权内容的游戏上架 Steam
站在社会的高度理解人工智能
AI连线 | 专访风平智能CEO林洪祥:让AI数字人拥有漂亮的外表和有趣的灵魂,安全问题是重要考量
小艺将具备大模型能力,鸿蒙4加速AI普及之路
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
美图秀秀“AI 扩图”功能上线,可根据图像生成更大画幅
新华社联合北大发布AI大模型评测:安全可靠成重点,360智脑表现优异
人脸识别+全景双摄+AI算法 萤石推动智能锁行业革新
OpenAI宣布组建新团队 以控制“超级智能”人工智能
云深处与昇腾CANN携手合作:开设ROS四足机器狗开发训练营
独家视角:首次展示有人与无人协同打击的7000米高空察打一体无人机
人工智能在重症监护室的未来
中国移动主导创立元宇宙产业联盟,包括科大讯飞、芒果TV等在内,共24家成员
微软大牛加入ZOOM,AI人才大战打响
天翼云在国际AI顶会大模型挑战赛中获得冠军
羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
世界人工智能大会机器人同台炫技!梳理A股相关业务营收占比超50%的个股名单
Zoom远程会议应用:AI培训需经用户授权
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
AI 程序 Text With Jesus 在海外迅速受到关注:与耶稣和撒旦进行对话
AI工具助力公司实施每周4.5天工作制,带来巨大效益
北京市元宇宙产业创新中心筹建工作正式启动
世界人工智能大会中西部县域数字就业中心组团亮相
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
浪潮KaiwuDB:“快人一步” - 打造更懂物联网的数据库
全新小艺搭载AI大模型,有效提升学生和职场人士的工作效率
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
笔神作文声讨学而思AI大模型 称用“爬虫”技术盗取数据
Midjourney 5.2震撼发布!原画生成3D场景,无限缩放无垠宇宙
看了天美对AI的布局,我感觉它想得是真明白
人工智能产业竞跑“未来赛道” 创新发展放大“赋能”效应
华为盘古AI模型实现秒级全球气象预报时间缩短
商汤科技:元萝卜 AI 下棋机器人新品发布会 6 月 14 日举行
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
OpenAI 向所有付费 API 用户开放 GPT-4
第二届光合组织AI解决方案大赛赛果揭晓
创新全场景清洁方案!海尔商用机器人首发上市
复旦发布「新闻推荐生态系统模拟器」SimuLine:单机支持万名读者、千名创作者、100+轮次推荐
OpenAI夺冠:人工智能为云计算带来新变革
鸿蒙4即将支持大规模AI模型
数据科学,解码智能未来——Altair首次提出“Frictionless AI”概念
酒店业将如何受益于人工智能的改变?
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

