


400 128 6709

行业新闻
 发布时间:2024-02-01
发布时间:2024-02-01 点击次数:
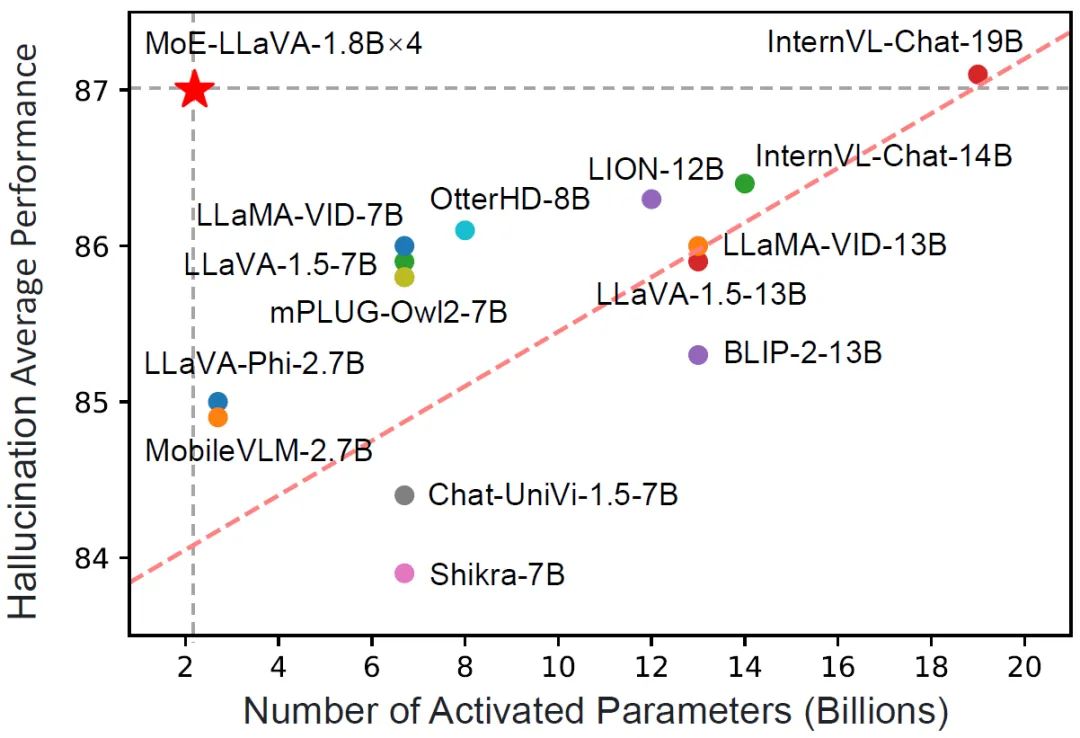
点击次数: 大型视觉语言模型(lvlm)可以通过扩展模型来提高性能。然而,扩大参数规模会增加训练和推理成本,因为每个token的计算都会激活所有模型参数。
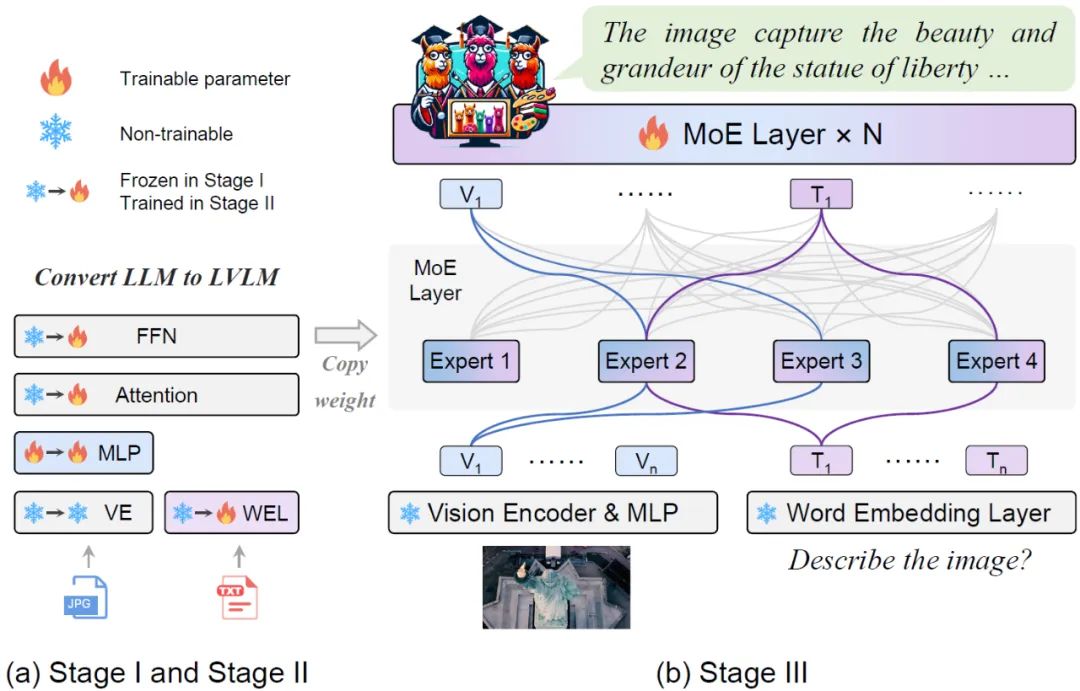
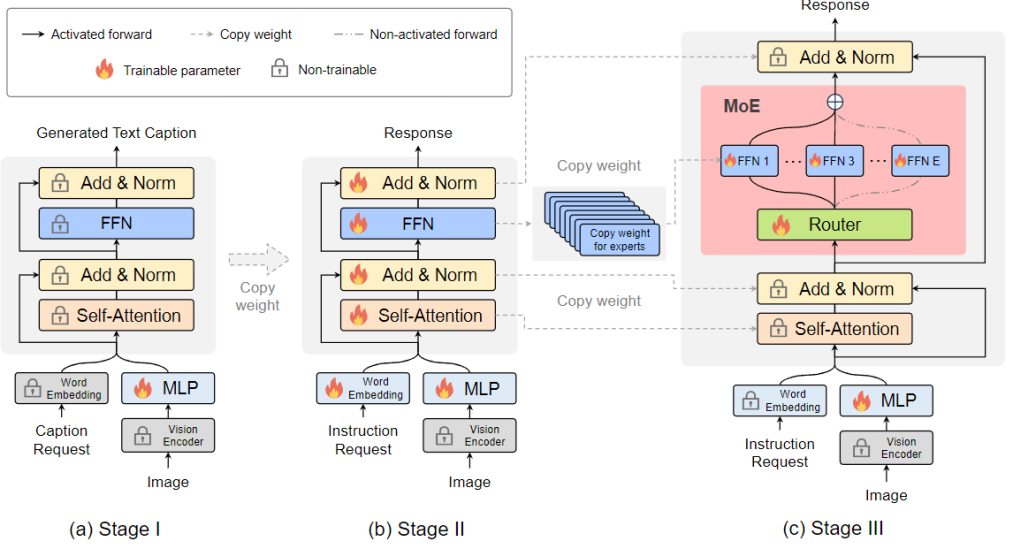
来自北京大学、中山大学等机构的研究者联合提出了一种新的训练策略,名为MoE-Tuning,用于解决多模态学习和模型稀疏性相关的性能下降问题。MoE-Tuning能够构建参数数量惊人但计算成本恒定的稀疏模型。此外,研究者还提出了一种基于MoE的新型稀疏LVLM架构,称为MoE-LLaVA框架。在这个框架中,通过路由算法仅激活前k个专家,其余专家保持非活动状态。通过这种方式,MoE-LLaVA框架在部署过程中能够更加高效地利用专家网络的资源。这些研究成果为解决LVLM模型在多模态学习和模型稀疏性方面的挑战提供了新的解决方案。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/abs/2401.15947
项目地址:https://github.com/PKU-YuanGroup/MoE-LLaVA
Demo地址:https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
论文题目:MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
 Machine Translation
Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情

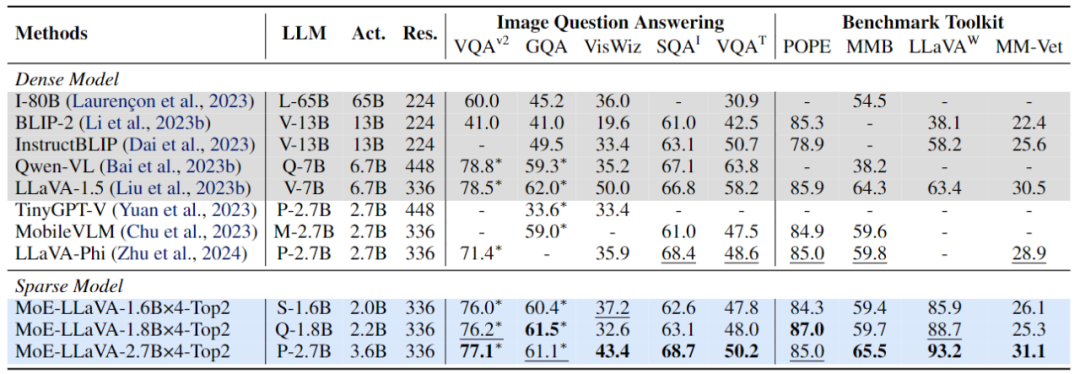
 达到和稠密模型相当甚至超过的性能。
达到和稠密模型相当甚至超过的性能。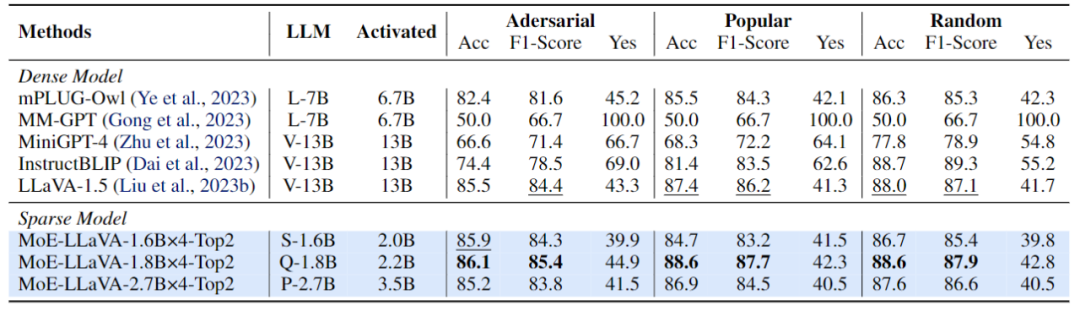
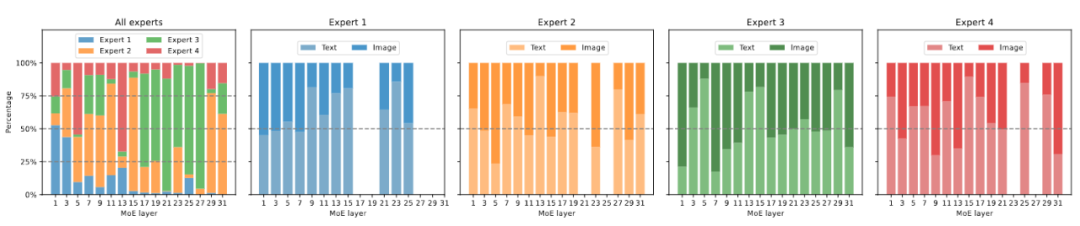
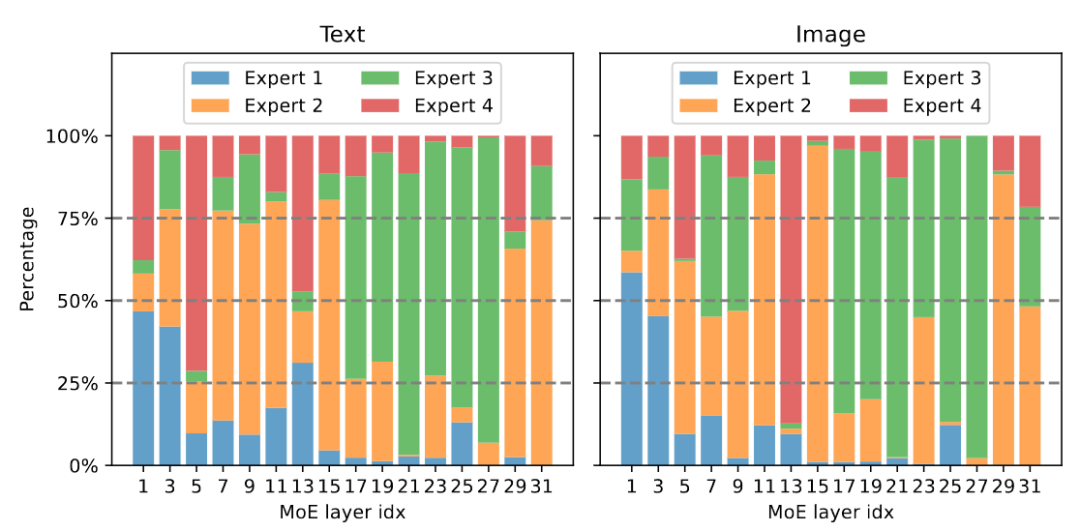
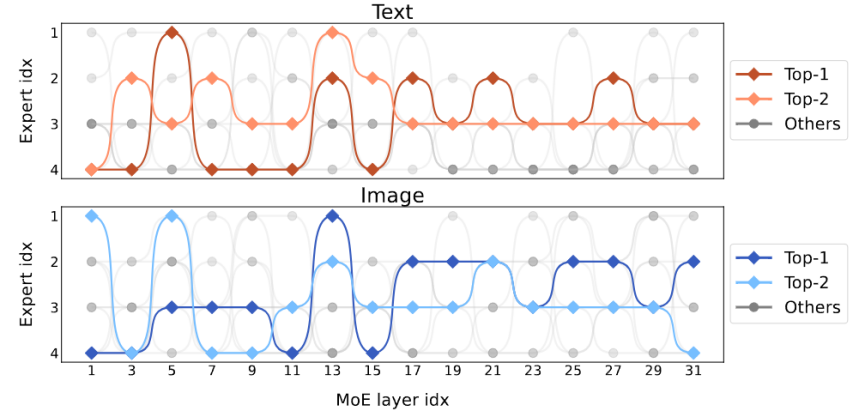
以上就是将多模态大模型稀疏化,3B模型MoE-LLaVA媲美LLaVA-1.5-7B的详细内容,更多请关注其它相关文章!
# 产业
# 提出了
# 营销推广就找j火20星
# 湖北网站优化案例分享
# 企业seo大概多少钱
# seo基础主治火星
# 廊坊seo工具
# 营销计划商品推广
# 离线推广电子商务网站
# 思享seo问答
# WIND数据网站建设
# 国学软文营销推广
# 超过了
# 模态
# 丰田
# 本田
# 的是
# 所示
# 如图
# 在这个
# 多模
# qwen
# 大型视觉语言模型
# 稀疏模型
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
微软商店 AI 摘要功能开启预览,帮助用户迅速了解应用评价
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
NVIDIA垄断AI市场90%份额:AMD性能追上80% 软件太不能打
美踏控股推出创新人工智能大数据模型“心乐舞河”:虚拟人音舞社交的新体验
京东 AI 大模型官宣 7 月 13 日发布,还有重磅合作
映宇宙集团执行总编辑:元宇宙还是要以人为媒介
用AI升级会议体验!思必驰多款会议产品亮相全球智博会!
如何用AI开创智慧能源新时代?固德威正让能源“通人性”!
500元一张的AI艺术二维码制作,详细教程来了!
当一个网站的内容被 AI 完全接管
人工智能正在弥合认知和表达之间的鸿沟
Unity 推出面向开发者的 AI 软件市场 AI Hub,股价飙涨 15%
2025年的网络分区:人工智能和自动化如何改变事物
微软为 AI 初学者推出免费网课:为期 12 周,共 24 节课
LinkedIn 推出生成式 AI 辅助撰写帖文功能,将向所有用户开放
AI时代,企业需要什么样的员工?
人工智能和神经网络有什么联系与区别?
科学家称,面对人工智能,人类未来或只有灭亡与虚拟永生两个选择
亲身体验鸿蒙4:AI大模型带来的便利,告别单纯的旁观者状态
2025世界人工智能大会成功召开
航拍无人机怎么选?大疆无人机盘点推荐
人工智能加速走进百姓生活:从2025全球人工智能技术大会看行业新趋势
人工智能颠覆软件测试四大方式
英伟达推出 L40S GPU,AI 推理性能超过 A100 约 1.2 倍
当孔子遇见AI|尼山的“数字”
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
眼球反射解锁3D世界,黑镜成真!马里兰华人新作炸翻科幻迷
OpenAI 向所有付费 API 用户开放 GPT-4
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
吉林首例!机器人辅助下搭桥手术成功实施
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
周鸿祎:用超级AI实现室温超导和核聚变,实现能源自由
Intel酷睿Ultra发布会官宣!迈向全新的AI时代
如何成功实施人工智能?
寻求能源转型最优解
当一切设备都受到人工智能的控制
「电子果蝇」惊动马斯克!背后是13万神经元全脑图谱,可在电脑上运行
AI绘画,还需要懂数学?
Goodnotes 6推出,带来多项全新AI功能,让电子笔记更智能
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
字节、网易相继入局,AI之后大厂又找到下一个风口?
直击上影节 | 光线传媒董事长王长田谈新技术:未来VR放映效果可能媲美影院
华为AI大模型将融入HarmonyOS 4
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
应对算力挑战,亚马逊云科技发力AI基础设施建设
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
日新月异,脑机接口技术都有哪些新应用?
苹果2万5的AR遭遇砍单95%:不及预期
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

